【基础学习笔记】Python学习笔记(2020年暑假归档)
这是我2020年暑假购买了自己的第一台笔记本电脑后第一次学习Python时,使用Typora敲下的第一份Markdown笔记,现在在自己的博客站上进行归档。

一、基础语法
1.出使Python国——Python概述、print()函数、 转义字符
(1)换行(newline,n):在执行完该语句后光标换行。
(2)水平制表符(tab,t):在水平方向以4个字符为一个单位设置空格。
示例:
1
print('hello\tworld')
结果:
1
hello world #中间有3个空格
分析:
| \t | \t | \t | \t | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| h | e | l | l | o | w | o | r | l | d |
(3)回车(return,r):光标会退至该语句执行前的位置,再执行其后的内容。
示例:
1
print('hello\rworld')
结果:
1
world
(4)退格(backspace,b):光标向前退一格再执行其后语句。
示例:
1
print('hello\bworld')
结果:
1
hellworld
(5)多反斜杠以及转义的取消
①多个反斜杠出现时,第一个反斜杠作为特殊转义字符不会被输出。
示例:
1
2
print('http:\\www.baidu.com')
print('http:\\\\www.baidu.com')
结果:
1
2
http:\www.baidu.com
http:\\www.baidu.com
②取消转义(原字符):在字符串前面加上r或者R均可取消转义。
(1)将数据输出到屏幕上
直接使用print(输出内容)即可完成此项输出。
(2)将数据输出到文件中(以txt文本文件为例)
1
2
3
文件名称 = open('路径/文件','a+') #使用a+表示若无此文件则创建该文件,若此文件已存在,则在已有文件末尾添加新的记录
print('内容',file=文件名称) #使用"/"来标识路径以防止意外转义情况发生
文件名称.close()
2.七十二变——字符编码方式、变量、数据类型、数据类型转换、注释
字符编码方式:
(1)中文:GB2312,GBK,GB18030,Unicode,UTF-8
(2)外文:ASCII,Unicode,UTF-8
(1)定义:对变量、函数、类、模块起的名称。
(2)注意事项:
①由字母、数字、下划线组成;
②开头必须是字母或者下划线,不能是其他字符;
③标识符不能是Python的保留字;
④Python中,标识符严格区分大小写;
⑤命名过程中,尽量遵循一定的规则,使得标识符意义明晰、无歧义,从而有利于后续代码的维护与修改。
Python中的保留字用以下方式输出:
1
2
import keyword
print(keyword.kwlist)
得到的结果是:
1
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
(1)变量概念的定义:内存中带标签的一个寄存器。
(2)变量的组成:标识、类型、值。
- 标识(
ID):表示对象所存储的内存地址,使用内置函数id()。 - 类型(
Class):表示对象的数据类型,使用内置函数type()来获取。 - 值(
Value):表示对象所存储的具体数据,使用内置函数print()可以将值进行打印输出。
(3)变量的定义:变量名 + 赋值运算符(=)+ 值。
在多次赋值后,变量名会指向新的空间,也就是改变其ID,旧有的变量就成为内存垃圾,由Python的垃圾回收机制进行回收。
(4)变量的使用:若要打印输出,则直接print(变量名)即可。在后续其他操作中,直接使用变量标识符进行操作。
(1)整数类型(integer,int):整数,正负以及零均可,在Python中默认以十进制表示,也可表示为二进制(在二进制数字前加上0b才会输出十进制数字,大小写不限,下同),八进制(0o)和十六进制(0x)。
(2)浮点数类型(float):带小数点的数字,由整数部分和小数部分组成。
注意事项:由于二进制的局限,浮点数存储并不精确,使用浮点数进行计算时,可能会出现小数位数不确定的情况。
示例:
1
2
print(1.1+2.2)
print(1.1+2.1)
结果:
1
2
3.3000000000000003
3.2
解决方案:导入decimal模块
1
2
from decimal import Decimal
print(Decimal('1.1')+Decimal('2.2'))
结果:
1
3.3
(3)布尔类型(boolean,bool):用来表示真或假的值,真-True(1),假-False(0),可以转化为整数进行计算。
示例:
1
2
print(True+1)
print(False+1)
结果:
1
2
2
1
(4)字符串类型(string,str):最常用的数据类型,又称为不可变的字符序列。
注意事项:
①可以使用单引号('')、双引号("")或三引号(''' '''或""" """)来定义;
②单引号和双引号定义的字符串必须在一行;
③三引号定义的字符串可以分布在连续的多行。
(1)目的:将不同类型的数据拼接在一起。
(2)数据类型转换函数:
str():将其他数据类型转换成字符串。注意事项:也可以使用引号转换。
float():将其他数据类型转换成浮点数。注意事项:①文字类无法转化成整数;②整数转化为浮点数,末尾为“
.0”。int():将其他数据类型转换成整数。注意事项:①文字类和小数类字符串,无法转化成整数;②浮点数转化成整数,会进行抹整取零操作,直接抹除小数点后的数字。
Python注释
(1)定义:在代码中对代码的功能进行解释说明的标注性文字,可以提高代码的可读性。注释的内容会被Python解释器忽略。
(2)类型:
①单行注释:以“#”开头,直到换行结束。
②多行注释:没有单独的多行注释标记,将一对三引号之间的代码称为多行注释。
③中文编码声明注释:在文件开头加上中文声明注释,用以指定源码文件的编码格式(Python默认为UTF-8)。例如:#coding:gbk。
3.算你赢——input()函数、运算符、运算符 优先级
(1)作用:接收来自用户的输入。
(2)返回值类型:字符串(str)。
(3)值的存储:使用“=”对输入的值进行存储。
(4)使用:
1
2
变量名 = input('在要求输入时显示的内容')
print(变量名)
input()函数可以与其他数据类型转换函数同时使用,例如:
1
int(input('请输入'))
得到的值就会是一个整数,而并非字符串。如果输入内容不是整数,则程序运行报错。
(1)算术运算符:分为标准算术运算符、取余运算符和幂运算符。
标准运算符:加(
+)、减(-)、乘(*)、除(/)、整除(//)例如:
11//2 = 5但是一正一负的时候需要向下取整,
例如:
-9//4 = -3取余运算符(模运算符):
%例如:
11%2 = 1但是一正一负的时候需要公式:
余数=被除数-除数*商,其中的商是整除的结果。例如:
-9%4 = 3
9%-4 = -3幂运算符:
**例如:
2**10 = 1024
(2)赋值运算符:=
注意事项:
①执行顺序从右到左,即先进行右侧的表达式计算,再存储到左侧变量中;
②支持链式赋值,链式赋值情况下,同时被赋值的变量ID相同,多个变量同时指向同一内存地址,例如:a=b=c=1;
③支持参数赋值:+=、-=、*=、/=、//=、%=
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
a=1
a+=1
print(a)
a-=1
print(a)
a*=100 #int
print(a)
a/=8 #float
print(a)
a//=2
print(a)
a%=3
print(a)
结果:
1
2
3
4
5
6
2
1
100
12.5
6.0
0.0
④支持系列解包赋值,注意等号左侧和右侧元素数目要相同,顺序要确定;
例如:
1
a,b,c=1,2,3
交换两个变量的值:
1
2
3
a,b=1,2
a,b=b,a
print(a,b)
结果:
1
2 1
(3)比较运算符:对变量或表达式的结果进行大小、真假等比较,包含“<”、“>”、“<=”、“>=”、“!=”、“==”、“is”、“is not”,得到的结果是布尔值。“is”、“is not”用于比较对象的标识(ID)。
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
a,b=1,2
print(a<b)
print(a>b)
print(a==b)
print(a<=b)
print(a>=b)
print(a!=b)
c,d=10,10
print(c is d)
list1=[1,2,3,4]
list2=[1,2,3,4]
print(list1==list2)
print(list1 is list2)
结果:
1
2
3
4
5
6
7
8
9
True
False
False
True
False
True
True
True
False
- 注意:列表(list)在比较
ID时,即使内容一样,其ID也不一样。
(4)布尔运算符:布尔值之间的运算,包含“and”、“or”、“not”、“in”、“not in”。
and:和运算符。要求其两端的布尔值均为True结果才为True。or:或运算符。要求其两端的布尔值至少一侧为True结果就为True。not:否运算符。将其右侧的布尔值转换为其相反值,即True转换为False,False转换为True。in、not in:检验运算符。检验左侧的元素是否在右侧变量中。
(5)位运算符:将数据转成二进制后进行计算,包含位与(&)、位或(|)、左移位运算符(<<)、右移位运算符(>>)。
位与(
&):将两侧两个数值的二进制数据逐位检验,只有当两个数据的对应位均为1时,输出的新二进制数据该位结果才为1。例如:
1 2 3
a = 0b00010001 b = 0b10010010 print(a&b)
结果:
1
16分析:
1 2 3 4 5
00010001 #a的值 10010010 #b的值 00010000 #a&b的值,对应十进制数据16
位或(
|):将两侧两个数值的二进制数据逐位检验,只有当两个数据的对应位均为0时,输出的新二进制数据该位结果才为0.例如:
1 2 3
a = 0b00010001 b = 0b10010010 print(a|b)
结果:
1
147分析:
1 2 3 4 5
00010001 #a的值 10010010 #b的值 10010011 #a|b的值,对应十进制数据147
左移位运算符(
<<):将原二进制数据向左移动一位,相当于原来的数据乘以2.若高位溢出,则在低位补0.示例:二进制数字4的左移
1 2 3
> 00000100 #对应十进制数字4 > 000001000 #对应十进制数字8,二进制数据整体左移一位后最高位0溢出,最右侧缺失一位,用0填充
右移位运算符(
>>):将原二进制数据向右移动一位,相当于原来的数据除以2.若低位截断,则在高位补0.示例:二进制数字4的右移
1
2
3
> 00000100 #对应十进制数字4
> 000000010 #对应十进制数字2,二进制数据整体右移一位后最低位0截断,最左侧缺失一位,用0填充
(1)运算类型优先级:算术运算(先算乘除,后算加减)、位运算、比较运算、布尔值运算、赋值运算。若有括号会先运算括号中的内容。
(2)具体运算符的优先级:
| 优先级 | 运算符 |
|---|---|
| 1 | ** |
| 2 | *,/,//,% |
| 3 | +,- |
| 4 | «,» |
| 5 | & |
| 6 | | |
| 7 | >,<,>=,<=,==,!= |
| 8 | and |
| 9 | or |
| 10 | = |
4.往哪儿走——顺序结构与分支结构
程序的组织结构大致可以分为三类:顺序结构、选择结构(if语句)、循环结构(while语句、for-in语句)。
程序从上到下顺序性地执行代码,中间没有任何的判断和跳转,直到程序结束。
流程:程序开始flag-------->代码1-------->代码2-------->……-------->代码n-------->程序结束flag
在Python中,一切皆对象,所有对象均对应一个布尔值。若要获取一个对象的布尔值,则使用内置函数bool()。
布尔值为False的对象:False、0、None、空字符串、空列表、空元组、空字典、空集合。
除了这些对象以外,其他对象的布尔值均为True。
程序根据判断条件的布尔值选择性地执行部分代码。作用是明确地让计算机知道在什么条件下该去做什么。if语句只接收并判定其后的对象的布尔值,然后决定执行的内容。
(1)单分支结构
①中文语义:如果……就……
②语法格式:
1
2
if 条件表达式: #冒号很重要
条件执行体 #4个空格的缩进很重要
(2)双分支结构
①中文语义:如果……不满足……就……
②流程示例图:
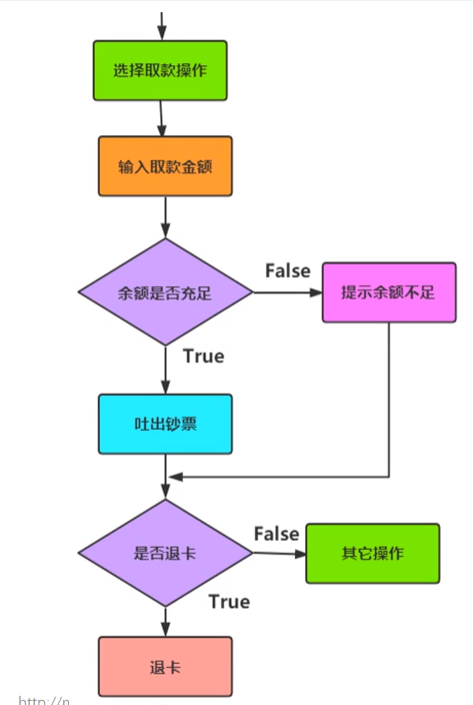
③语法格式:
1
2
3
4
if 条件表达式: #冒号很重要
条件执行体1 #4个空格的缩进很重要
else: #冒号很重要
条件执行体2 #4个空格的缩进很重要
(3)多分支结构
①中文语义:……满足……吗?不满足。
那么……满足……吗?不满足。
那么……满足……吗?不满足。
那么……满足……吗?满足。
总的来说,就是多选一执行。
②流程示例图:
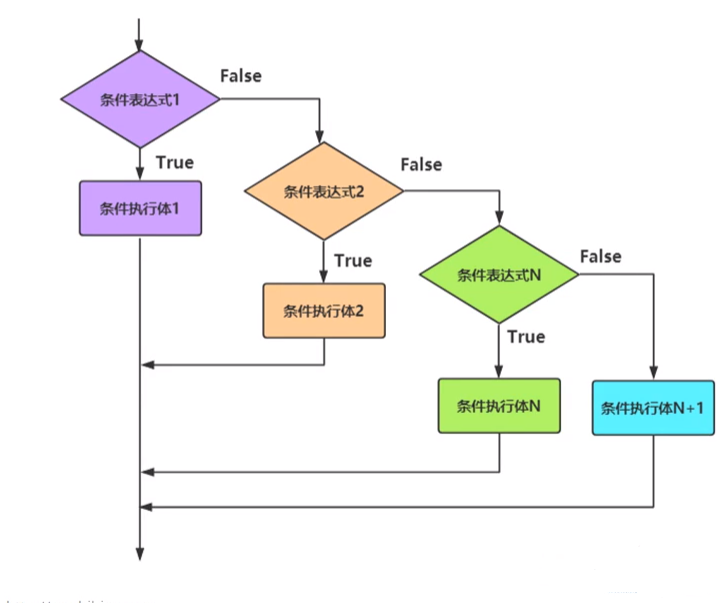
③语法格式:
1
2
3
4
5
6
7
8
9
if 条件表达式1: #冒号
条件执行体1 #缩进
elif 条件表达式2:#冒号
条件执行体2 #缩进
……
elif 条件表达式n: #冒号
条件执行体n #缩进
else: #冒号
条件执行体(n+1) #缩进
- 注意:在多分支结构中,在没有条件例外的情况时,最后一个“
else:”可以不写。
(4)if嵌套
①语法格式:
1
2
3
4
5
6
7
if 外层条件表达式: #冒号
if 内层条件表达式: #冒号和4个空格的缩进很重要
内层代码执行体1 #4个空格的缩进很重要,要在上一级缩进的基础上继续缩进4空格
else: #冒号和4个空格的缩进很重要
内层代码执行体2 #4个空格的缩进很重要,要在上一级缩进的基础上继续缩进4空格
else: #冒号
外层条件执行体2 #缩进
②流程示例图:
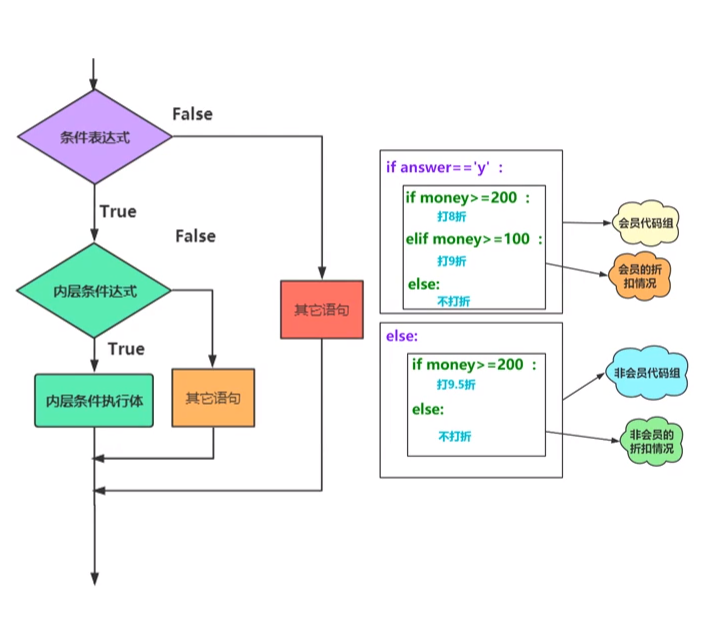
(5)条件表达式
①基本含义:条件表达式是if……else的简写。
②语法格式:
1
x if 判断条件 else y
③运算规则:如果判断条件的布尔值为True,条件表达式的返回值为x,否则条件表达式返回的值为y。
④示例:
1
2
3
4
5
num1 = int(input('请输入第一个整数:'))
num2 = int(input('请输入第二个整数:'))
print((num1,'大于等于',num2) if num1 >= num2 else (num1,'小于',num2)) #条件表达式输出1
print(str(num1)+'大于等于'+str(num2) if num1 >= num2 else str(num1)+'小于'+str(num2)) #条件表达式输出2
print(str(num1)+'大于等于'+str(num2)) if num1 >= num2 else print(str(num1)+'小于'+str(num2)) #条件表达式输出3
输入:
1
2
10
20
结果:
1
2
3
(10, '小于', 20)
10小于20
10小于20
(1)概述:pass语句什么都不做,只是一个占位符,用在语法上需要语句的地方。
(2)适用场合:先搭建语法结构,但尚未想好代码怎么写的时候使用,可以使语法不报错。
(3)与哪些语句一起使用:if语句的条件执行体、for-in语句的循环体、定义函数时的函数体。
(4)示例:
1
2
3
4
if 条件表达式:
pass
else:
pass
5.转圈圈——while与for-in循环、循环控制语句break、continue、else
(1)作用:用于生成一个整数序列。
(2)创建range对象的三种方式:
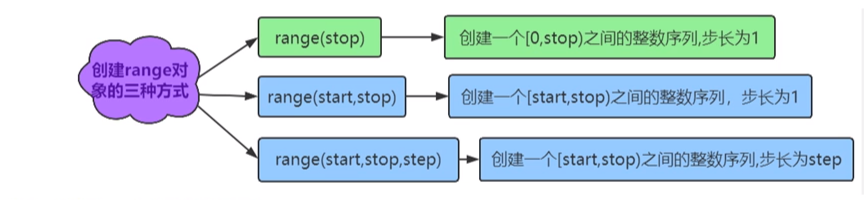
- 注意:在创建迭代范围的时候,区间左闭右开。
(3)返回值:一个迭代器对象,无法直接罗列出具体整数序列。若要罗列,使用print(list(range()))。
(4)range类型优点:不管range对象表示的整数序列有多长,所有range对象占用的内存空间都是相同的。因为仅仅需要存储start,stop和step,只有当用到range对象时,才会去计算序列中的相关元素。
(5)in与not in语句用来判断某个整数是否存在于该序列中,返回值为布尔值。
示例:
1
2
3
4
r = range(0,10,2)
print(list(r))
p = 9 in r
print(p)
结果:
1
2
[0, 2, 4, 6, 8]
False
(1)定义:反复做同一件事情的情况,称为循环。
(2)循环结构流程图示:
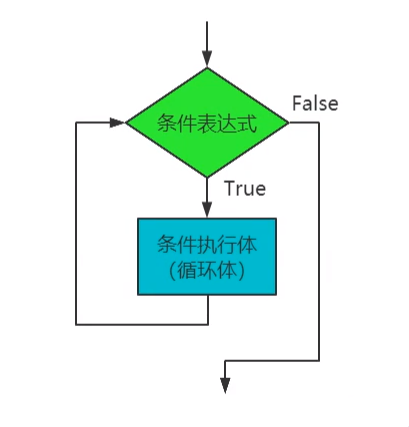
(3)循环的分类:while循环与for-in循环。
(4)选择结构的if与循环结构的while的区别:
①if是判断一次,条件为True则执行一次;
②while是判断n+1次后得到False,而条件为True时执行了n次。
(1)语法格式:
1
2
while 条件表达式 :
条件执行体(循环体) #注意缩进
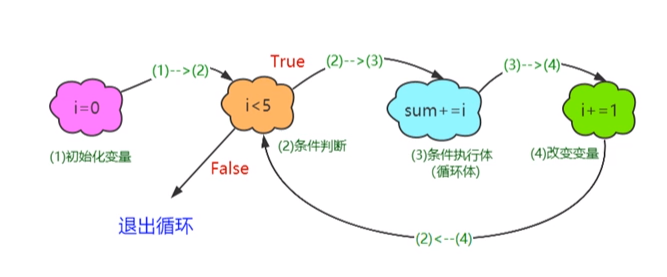
(2)四步循环法:
①初始化变量
②条件判断
③条件执行体(循环体)
④改变变量
- 注意:初始化变量、条件判断变量和改变的变量为同一个变量。
(3)while循环的执行流程:
(4)示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#while循环的使用:求1到100之间所有的奇数和
a = 1
sum = 0
while a <= 100:
if a%2: #当判断条件的布尔值为True时才会执行下面的代码,原本应该写成if a%2 == 0,但是由于0的布尔值为False,所以不必要写出.当a为奇数时,a除以2余数不为0,布尔值为True.
sum += a
a += 1
print('1到100之间的所有奇数和为:',sum)
#while循环的使用:求1到100之间所有的偶数和
a = 1
sum = 0
while a <= 100:
if not bool(a%2): #这一步与上面的刚好相反,取反判断条件的布尔值,从而达到在a为偶数时执行下面的代码的目的
sum += a
a += 1
print('1到100之间的所有偶数和为:',sum)
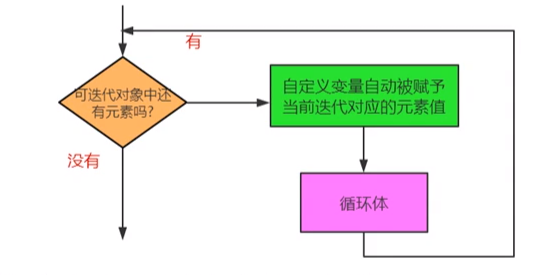
(1)in的含义:表达从字符串、序列等中依次取值,又称为遍历。for-in的遍历对象必须是可迭代对象。
(2)语法格式:
1
2
for 自定义的变量 in 可迭代对象:
循环体 #注意4个空格的缩进
(3)for-in循环的执行流程图:
(4)注意事项:循环体内不需要访问自定义变量,可以将自定义变量替换为下划线(_)。
示例:
1
2
for _ in range(3):
print('人生苦短,我用Python')
结果:
1
2
3
人生苦短,我用Python
人生苦短,我用Python
人生苦短,我用Python
(1)作用:用于结束循环结构,通常与分支结构if一起使用。
(2)作用示例图:
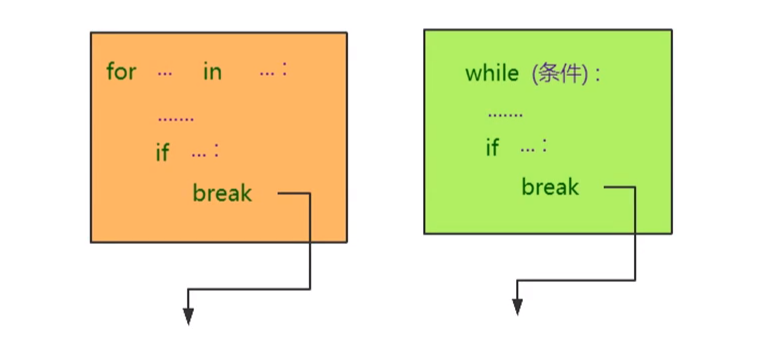
(3)示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#break结束循环:
for a in range(3):
pwd = input('请输入密码:')
if pwd == '8888':
print('密码正确')
break
else:
print('密码不正确')
#break与while语句一起使用的另一种写法:
a = 0
while a <= 2:
pwd = input('请输入密码:')
if pwd == '8888':
print('密码正确')
break
else:
print('密码不正确')
a += 1
(1)作用:用于结束当前循环,进入下一次循环,通常与分支结构中的if一起使用。相当于跳过了这次循环体的执行。
(2)作用示例图:
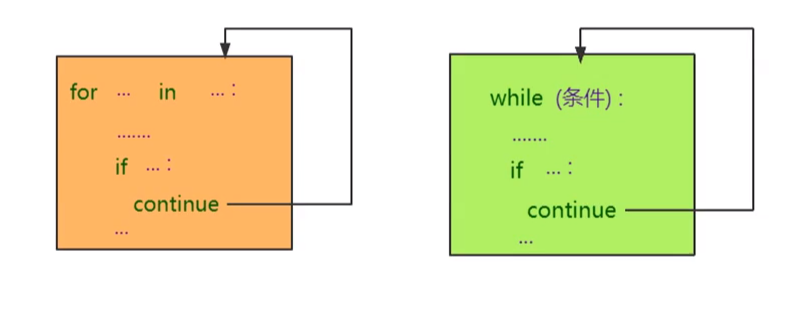
(3)示例代码:
1
2
3
4
5
6
#continue语句的使用:输出1到50之间所有的5的倍数
for item in range(1,51):
if item%5 != 0:
continue
else:
print(item)
结果:
1
2
3
4
5
6
7
8
9
10
5
10
15
20
25
30
35
40
45
50
(1)与else语句配合使用的三种情况:
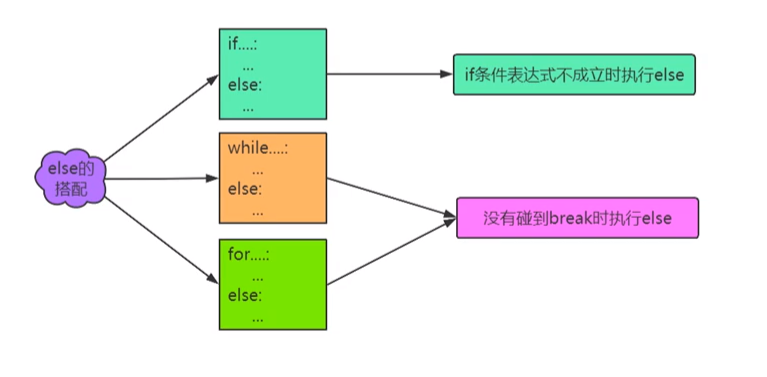
- 注意:在
for和while循环中,如果循环所有次数都执行完毕,中途没有遇到break,则执行else后的代码,否则不执行else后的代码。
(2)示例代码:
①与for共同使用:
1
2
3
4
5
6
7
8
9
for a in range(3):
pwd = input('请输入密码:')
if pwd == '8888':
print('密码正确')
break
else:
print('密码不正确')
else:
print('对不起,三次密码均输入错误!')
②与while共同使用:
1
2
3
4
5
6
7
8
9
10
11
a = 0
while a <= 2:
pwd = input('请输入密码:')
if pwd == '8888':
print('密码正确')
break
else:
print('密码不正确')
a += 1
else:
print('对不起,三次密码均输入错误!')
(1)定义:循环结构中又嵌套了其他的循环结构,其中内层循环作为外层循环的循环体执行。
(2)示意图:
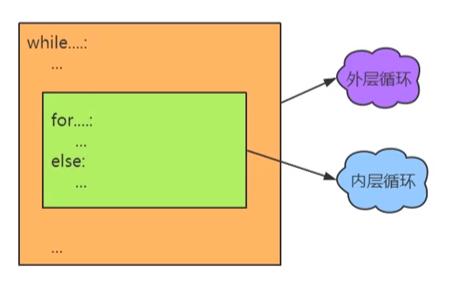
(3)示例代码:
①输出一个3行4列的“*”矩形:
1
2
3
4
for i in range(1,4):
for j in range(1,5):
print('',end='\t') #不换行输出
print() #换行
②输出9行的“*”直角三角形:
1
2
3
4
for i in range(1,10):
for j in range(1,i+1):
print('*',end = '\t')
print()
③输出九九乘法表:
1
2
3
4
for i in range(1,10):
for j in range(1,i+1):
print(i,'*',j,'=',i*j,end='\t')
print() #换行
(1)作用:用于控制本层循环,在循环执行过程中,遇到的break只退出本层循环,对另一层没有影响;遇到的continue只跳过本层循环的该轮循环,对另一层没有影响。
(2)示意图:
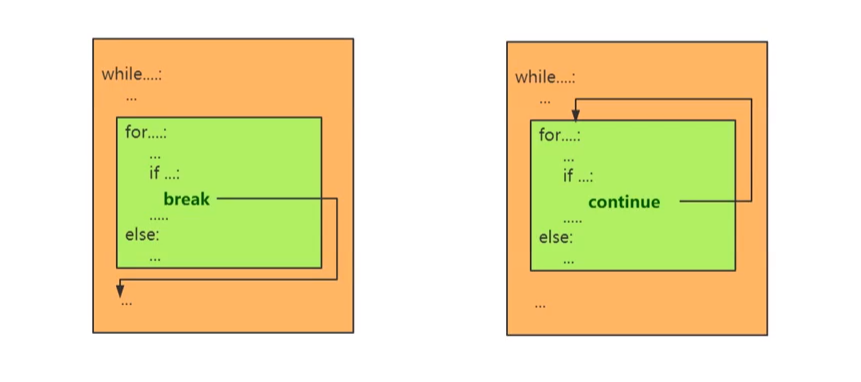
(3)示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
#二重循环中的break与continue:二重for循环中的break
for i in range(5): #外层循环要执行5次
for j in range(1,11):
if j%2==0:
break
print(j)
#二重循环中的break与continue:二重for循环中的continue
for i in range(5): #外层循环要执行5次
for j in range(1,11):
if j%2==0:
continue
print(j,end='\t')
print()
结果:
1
2
3
4
5
6
7
8
9
10
1
1
1
1
1
1 3 5 7 9
1 3 5 7 9
1 3 5 7 9
1 3 5 7 9
1 3 5 7 9
6.一字排开——数据结构:列表
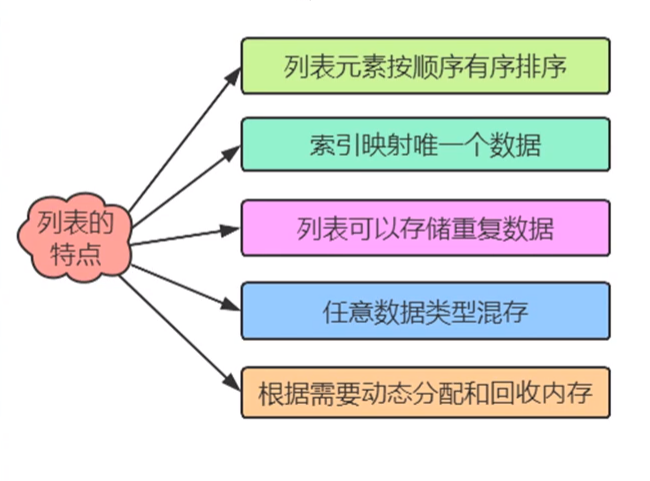
(1)变量可以存储一个元素,而列表可以存储很多元素,程序可以方便地对这些数据进行整体操作。
(2)变量只存储一个对象的引用(ID),而列表可以同时存储很多对象的引用。列表本身也有一个引用(ID),列表内部的内存空间为连续空间。
(3)列表相当于其他语言中的数组。列表中的元素可以重复。
(4)列表示意图:

(1)列表需要使用方括号([ ])标示,元素之间使用英文逗号(,)进行分隔。
(2)使用方括号([ ]):
1
list1 = ['1','2','3']
(3)使用内置函数list():
1
list2 = list(['1','2','3'])

(1)获取列表中指定元素的索引

示例:
1
2
3
4
list = ['1','2','3','1']
print(list.index('1'))
print(list.index('Python'))
print(list.index('3',1,4))
结果:
1
2
3
0
ValueError: 'Python' is not in list
2
- 注意:查找索引时使用的
[start,stop]也是左闭右开区间。当列表中存在相同元素时,index()函数默认获取第一个该元素的索引。
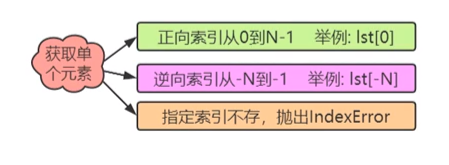
(2)获取列表中的单个元素
示例:
1
2
3
4
list = ['1','2','3','1']
print(list[0])
print(list[-1])
print(list[10])
结果:
1
2
3
1
1
IndexError: list index out of range
(3)获取列表中的多个元素(切片操作)
①语法格式:
1
列表名[start:stop:step]
注意:
[start:stop]为左闭右开区间,切片不包含stop索引的元素。②示意图:
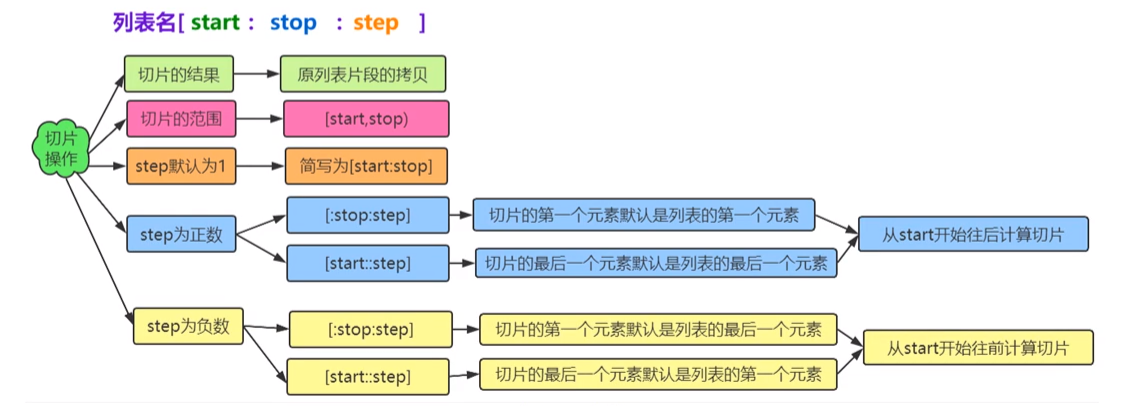
注意:
Ⅰ.切片得到的对象是一个具有新的
ID的独立对象。Ⅱ.步长省略(缺省值为1)的写法有两种:
[start:stop]或[start:stop:]。Ⅲ.
strat也可省略,默认从列表第一个元素开始向后切片,格式为[:stop:step]。Ⅳ.
stop也可省略,默认从列表最后一个元素开始向前切片,格式为[start::step]。Ⅴ.步长为负数时,
start要比stop大,切片顺序为原列表中从后往前。
(4)判断指定元素在列表中是否存在
语法格式:
1
2
元素 in 列表名
元素 not in 列表名
返回值为一个布尔值。
(5)列表元素的遍历
语法格式:
1
2
for 迭代变量 in 列表名:
操作
(1)增加操作:增加操作后,列表的ID不会发生改变,仍然是原来的列表对象。
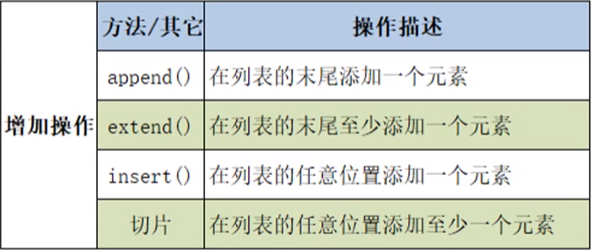
①append()(添加):在列表的末尾添加一个元素。也可以把一个列表添加到另一个列表中。
示例:
1
2
3
4
list1 = [10,20,30]
list2 = ['hello','world']
list1.append(list2) #将list2作为一个元素添加到列表list1的末尾
print(list1)
结果:
1
[10, 20, 30, ['hello', 'world']]
②extend()(扩展):在列表的末尾添加至少一个元素。
示例:
1
2
3
4
list1 = [10,20,30]
list2 = ['hello','world']
list1.extend(list2) #将list2中的元素添加到列表list1的末尾
print(list1)
结果:
1
[10, 20, 30, 'hello', 'world']
③insert()(插入):在一个列表的任意位置添加一个元素。
语法格式:
1
列表名.insert(索引号,元素)
示例:
1
2
3
list1 = [10,20,30]
list1.insert(1,40) #在列表list1索引为1的位置插入元素40
print(list1)
结果:
1
[10, 40, 20, 30]
④切片:在列表的任意位置添加至少一个元素。可以理解为先切除,再添加。
语法格式:
1
列表名1[start:stop] = 列表名2
示例:
1
2
3
list1 = [10,20,30]
list2 = ['hello','world']
list[1:] = list2 #将列表list1索引号1及其后的所有元素替换为列表list2中的元素
结果:
1
[10, 'hello', 'world']
(2)删除操作:删除操作后,列表的ID不会发生改变,仍然是原来的列表对象。
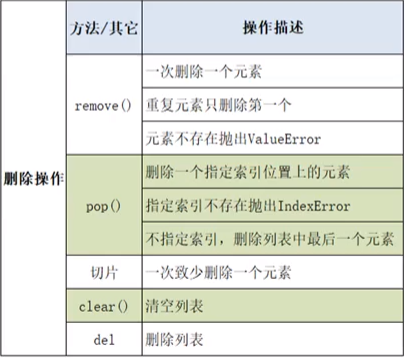
①remove()(移除):删除列表中一个指定的元素。如果元素重复,则只删除第一个。若指定元素不存在,则报错为ValueError。
示例:
1
2
3
4
list = [10,20,30]
list.remove(10)
print(list)
list.remove(100)
结果:
1
2
[20, 30]
ValueError: list.remove(x): x not in list
②pop()(指定索引删除):删除列表中一个指定索引位置上的元素。如果不指定索引,则默认删除列表中最后一个元素。若指定元素不存在,则报错为IndexError。
示例:
1
2
3
4
list = [10,20,30]
list.pop(1)
print(list)
list.pop(10)
结果:
1
2
[10, 30]
IndexError: pop index out of range
③切片:一次至少删除一个元素。但需要注意的是,切片操作后会产生一个新的列表对象,ID不相同。
示例:
1
2
3
4
list1 = [10,20,30]
list2 = list1[1:2]
print(list1,id(list1))
print(list2,id(list2))
结果:
1
2
[10, 20, 30] 1849192874560
[20] 1849193187456
如果需要不产生新的列表元素的切片,则使用下面的方法,用空列表代替切片删除的位置:
1
2
3
4
list = [10,20,30]
print(list,id(list))
list[1:3] = []
print(list,id(list))
结果:
1
2
[10, 20, 30] 2261203207424
[10] 2261203207424
④clear()(清除):清除列表中的所有元素,使原列表成为空列表,但仍然存在。
用法:
1
列表名.clear()
⑤del(删除):删除列表对象,原列表在执行该操作后不存在。
用法:
1
del 列表名
(3)修改操作
①为指定索引的元素赋予一个新值
语法格式:
1
列表名[索引号] = 新元素的值
②为指定的切片赋予一个新值
语法格式:
1
列表名[start:stop] = [元素1,元素2,元素3……] #注意切片内元素的数量左右要一致
(1)排序的两种常见方式
①调用sort()方法,把列表中所有元素按照从小到大的顺序进行排序,默认为升序(也即reverse=False),可以指定reverse=True进行降序排序。排序后,列表的ID不发生改变。
示例:
1
2
3
4
5
6
7
8
list = [1,2321,3423,201,124324]
print(list,id(list))
list.sort()
print(list,id(list))
list.sort(reverse=True)
print(list,id(list))
list.sort(reverse=False)
print(list,id(list))
结果:
1
2
3
4
[1, 2321, 3423, 201, 124324] 2535163039168
[1, 201, 2321, 3423, 124324] 2535163039168
[124324, 3423, 2321, 201, 1] 2535163039168
[1, 201, 2321, 3423, 124324] 2535163039168
②调用内置函数sorted(),可以指定reverse=True进行降序排序。排序后,将会产生一个ID不同的新的列表对象,原列表不发生改变。
示例:
1
2
3
4
5
6
7
8
list = [1,2321,3423,201,124324]
print('原列表',list,id(list))
new_list = sorted(list)
print('新列表',new_list,id(new_list))
new_list = sorted(list,reverse=True)
print('新列表',new_list,id(new_list))
new_list = sorted(list,reverse=False)
print('新列表',new_list,id(new_list))
结果:
1
2
3
4
原列表 [1, 2321, 3423, 201, 124324] 2510529348864
新列表 [1, 201, 2321, 3423, 124324] 2510529039744
新列表 [124324, 3423, 2321, 201, 1] 2510529350336
新列表 [1, 201, 2321, 3423, 124324] 2510529039744
(1)定义:“生成列表的公式”简称列表生成式,作用是生成一个列表对象。
(2)语法格式:
1
列表名 = [表示列表元素的表达式 for 自定义变量 in range(start,stop)]
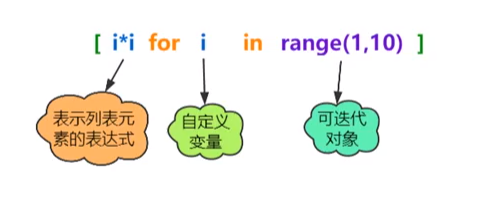
表示列表元素的表达式:列表中所真正包含的元素的值。
自定义变量:需要迭代的变量。
可迭代对象:自定义变量的迭代范围。
注意事项:“表示列表元素的表达式”中通常包含自定义变量。使用列表生成式时,列表中的对象必须具有一定的规律,可以迭代。
示例:
1
2
3
4
list1 = [i*i for i in range(1,10) ]
print(list1)
list2 = [i*2 for i in range (1,6)]
print(list2)
结果:
1
2
[1, 4, 9, 16, 25, 36, 49, 64, 81]
[2, 4, 6, 8, 10]
7.夫妻站——数据结构:字典
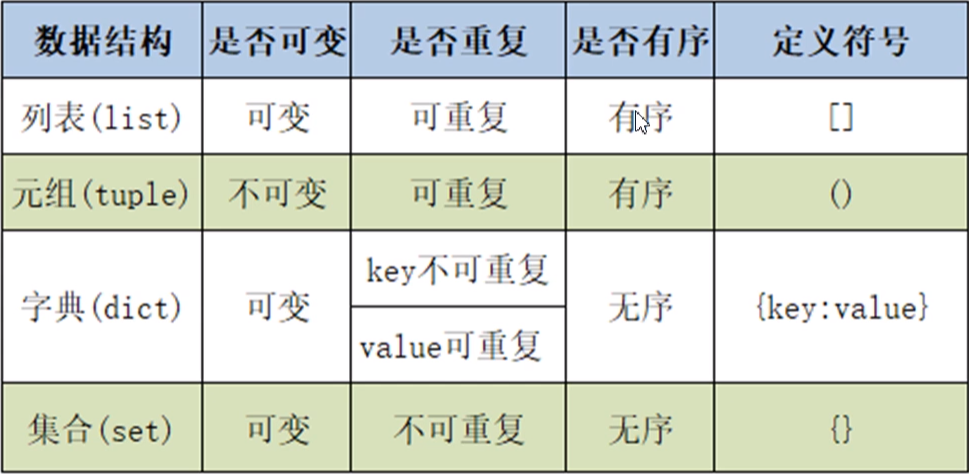
学习内容:什么是字典、字典的原理、字典的创建与删除、字典的查询操作、字典元素的增删改操作、字典的视图操作、字典的特点、字典生成式
什么是字典
(1)字典是Python内置的数据结构之一,与列表一样是一个可变序列(即可以进行增删改操作)。
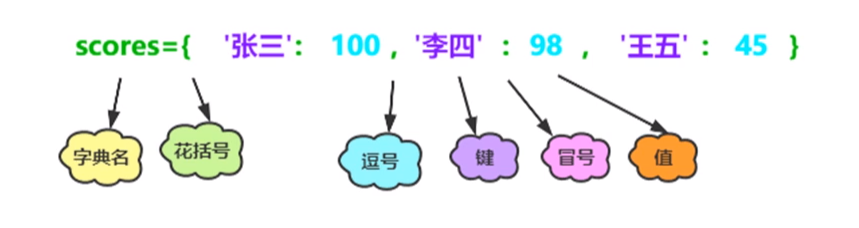
(2)字典以键值对的方式存储数据,键值对是由键与值组成,格式为“
键:值”。值可以是字符串、数字甚至是列表。(3)区别于列表,字典是一个无序的序列,即添加进字典的元素并不一定按照添加的顺序排列。
(4)字典在Python中使用花括号(
{ })进行定义。
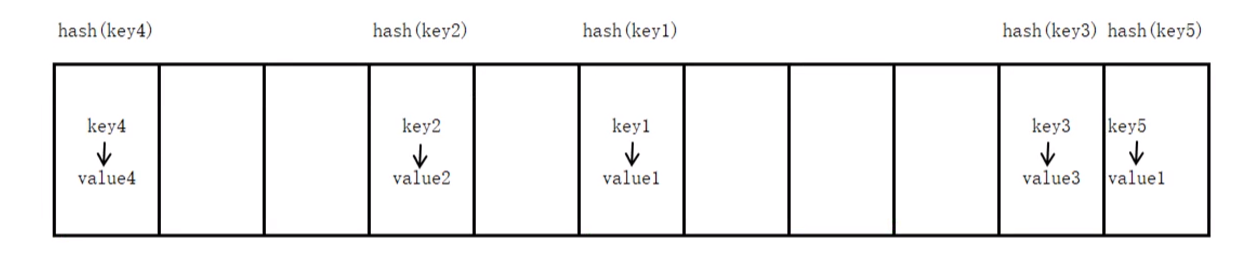
(1)字典的实现原理与查字典类似,现实中的字典先根据不收或者拼音查找对应的页码,Python中的字典是根据key查找value的位置。
(2)放在字典中的key由hash值代替,由key计算出hash值后存储在字典中,这个计算过程相当于现实字典中对于汉字部首或者拼音的定义。
(1)字典需要使用花括号({ })标示,元素之间使用英文逗号(,)进行分隔。
(2)使用花括号({ }),这是最常见的方式:
1
字典名 = {key1:value1,key2:value2,……}
(3)使用内置函数dict():
1
字典名 = dict(key1:value1,key2:value2,……)
(4)空字典的创建:
1
2
字典名 = {}
字典名 = dict()
(1)字典中元素的获取
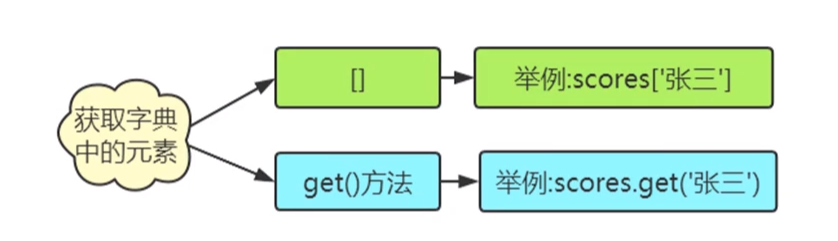
①使用方括号([ ])取值。如果字典中不存在指定的key,则报错为keyError。
语法格式:
1
字典名[key]
示例:
1
2
3
scores = {'张三':100,'李四':98,'王五':45}
print(scores['张三'])
print(scores['赵六'])
结果:
1
2
100
KeyError: '赵六'
②使用get()方法取值。如果字典中并不存在指定的key,则返回值为None而不是keyError报错。可以通过参数设置默认的value,以便指定的key不存在时返回。
语法格式:
1
字典名.get(key)
示例:
1
2
3
scores = {'张三':100,'李四':98,'王五':45}
print(scores.get('张三'))
print(scores.get('赵六'))
结果:
1
2
100
None
在使用该方法查找的元素在字典中不存在时,可以通过设置给予其返回的默认值,例如:
1
2
3
scores = {'张三':100,'李四':98,'王五':45}
print(scores.get('张三'))
print(scores.get('赵六',99))
结果:
1
2
100
99
(2)指定key在字典中存在性的判断
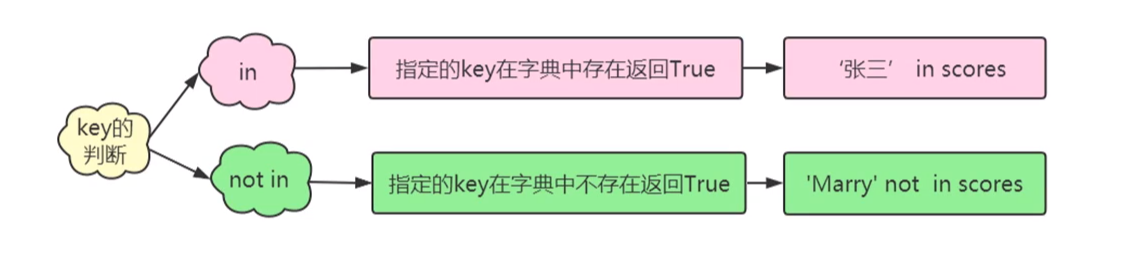
使用in/not in语句判断指定key在字典中是否存在,返回值为一个布尔值。
示例:
1
2
3
scores = {'张三':100,'李四':98,'王五':45}
print('张三' in scores)
print('张三' not in scores)
结果:
1
2
True
False
(3)字典元素的删除
①单个指定key元素的删除
语法格式:
1
del 字典名[key]
②清空字典
语法格式:
1
字典名.clear()
(4)字典元素的新增
语法格式:
1
字典名[key] = value
其中的key须是字典中没有的key,否则就为修改元素。
(5)字典元素的修改
语法格式:
1
字典名[key] = value
其中的key须是字典中已有的key,否则就为新增元素。
(6)字典的视图操作
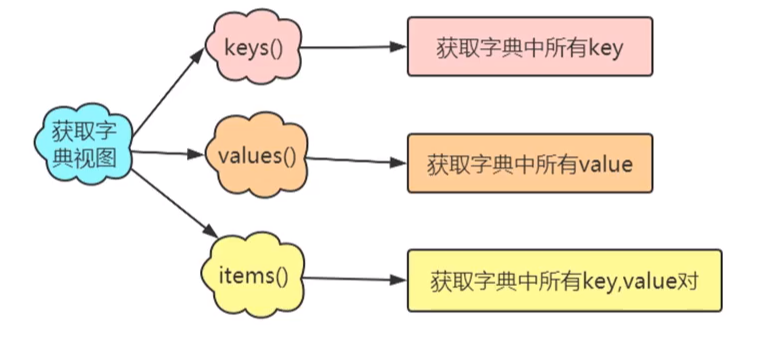
①keys():获取字典中所有的key。
示例:
1
2
3
4
5
scores = {'张三':100,'李四':98,'王五':45}
keys = scores.keys()
print(keys)
print(type(scores))
print(list(keys)) #将字典中所有key组成的视图转换为列表
结果:
1
2
3
dict_keys(['张三', '李四', '王五'])
<class 'dict'>
['张三', '李四', '王五']
②values():获取字典中所有的value。
示例:
1
2
3
4
scores = {'张三':100,'李四':98,'王五':45}
values = scores.values()
print(values)
print(list(values)) #将字典中所有value组成的视图转换为列表
结果:
1
2
dict_values([100, 98, 45])
[100, 98, 45]
③items():获取字典中所有的元素,以键值对形式存储。
示例:
1
2
3
4
scores = {'张三':100,'李四':98,'王五':45}
items = scores.items()
print(items) #得到的item数据形式为元组
print(list(items)) #将字典中所有item元组组成的视图转换为列表
结果:
1
2
dict_items([('张三', 100), ('李四', 98), ('王五', 45)])
[('张三', 100), ('李四', 98), ('王五', 45)]
(7)字典元素的遍历
语法格式:
1
for 自定义变量 in 字典名:
示例:
1
2
3
scores = {'张三':100,'李四':98,'王五':45}
for item in scores: #遍历的对象是key,不包含value
print(item,scores[item],scores.get(item))
结果:
1
2
3
张三 100 100
李四 98 98
王五 45 45
(1)字典中所有元素都是一个key-value对,key不允许重复但是value可以重复,类似于数学中的函数映射关系。
(2)字典中的元素是无序的,不像列表一样具有索引,是由key计算出value的位置,无法手动指定元素在字典中的的位置。
(3)字典中的key必须是不可变对象,比如整数、字符串,列表或是其他字典等不可变对象不可以作为key,因为可变对象无法通过计算得到一个恒定的hash值。
(4)字典可以根据需要动态地伸缩。
(5)字典会浪费较大的内存,元素之间的空白内存空间并不可以被其他部分利用,是一种用空间换时间的数据结构,但是查找速度很快。
(1)内置函数zip():用于将可迭代对象作为参数,将对象中对应的元素打包成一个元组,然后返回由这些元组组成的列表。在zip()打包执行过程中,以少的那个可迭代对象中的内容数量作为key-value对的数目。
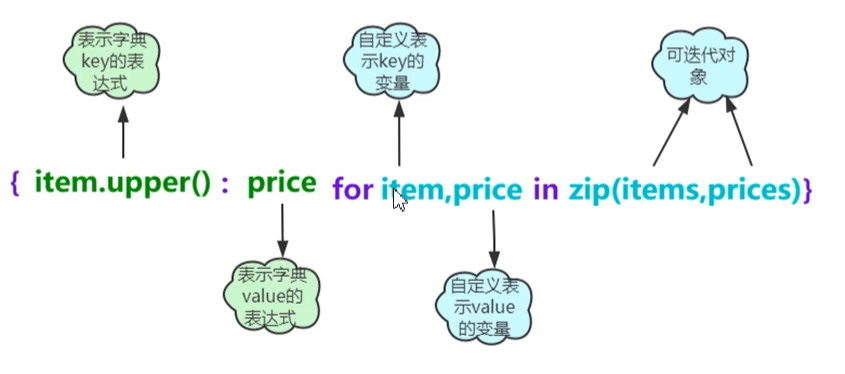
语法格式:
1
字典名 = {key:value for key,value in zip(可迭代对象1,可迭代对象2)}
示例:
1
2
3
4
5
6
items = ['Fruits','Books','Others']
prices = [96,78,85,100,123]
dict1 = {item:price for item,price in zip(items,prices)}
dict2 = {item.upper():price for item,price in zip(items,prices)} #upper()函数的作用是将其跟着的变量中的所有字母大写
print(dict1)
print(dict2)
结果:
1
2
{'Fruits': 96, 'Books': 78, 'Others': 85}
{'FRUITS': 96, 'BOOKS': 78, 'OTHERS': 85}
8.是排是散——数据结构:元组
学习内容:什么是元组、不可变序列与可变序列、元组的创建、元组设计成不可变序列的原因、元组中元素的获取、什么是集合、集合的创建、集合的查询操作、集合的增删改操作、集合间的关系、集合的数学操作、集合生成式
什么是元组(
tuple)(1)概念:元组是Python内置的数据结构之一,是一个不可变序列,但是是一个有序序列,支持索引。
(2)示意图:
(1)根本区别:是否可以进行增删改操作。
(2)不可变序列:字符串、元组。不能进行增删改操作。
(3)可变序列:列表、字典。进行增删改操作后,对象的地址(ID)不发生改变。
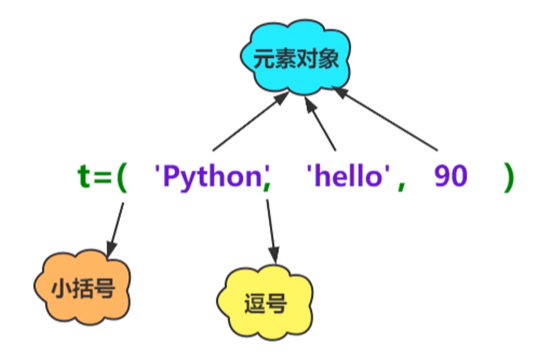
(1)元组需要使用圆括号(( ))标示,元素之间使用英文逗号(,)进行分隔。
(2)直接使用圆括号:
1
元组名 = ('Python','hello','90')
但是元组中有多个元素的时候可以省略小括号:
1
元组名 = 'Python','hello','90'
(3)使用内置函数tuple():
1
元组名 = tuple(('Python','hello','90'))
(4)只包含一个元素的元组需要使用逗号和小括号:
1
元组名 = (1,)
(5)空元组的创建
1
2
元组名 = ()
元组名 = tuple()
(6)元组是不可变序列,因此没有元组生成式,不能使用生成式创建元组。
(1)原因:
①一旦对象被创建之后,对象内部的数据就不可修改,可以避免因修改数据带来的错误。
②对于不可变对象,在多任务环境下,多个主体同时操作同一对象时不需要加锁,因此在程序中尽量使用不可变序列。
(2)注意事项:
①元组中存储的是对象的引用。
②如果元组中对象本身是不可变对象,则不能再引用其他对象。
③如果元组中的对象是可变对象,则可变对象的引用不允许改变,但是数据可以改变。
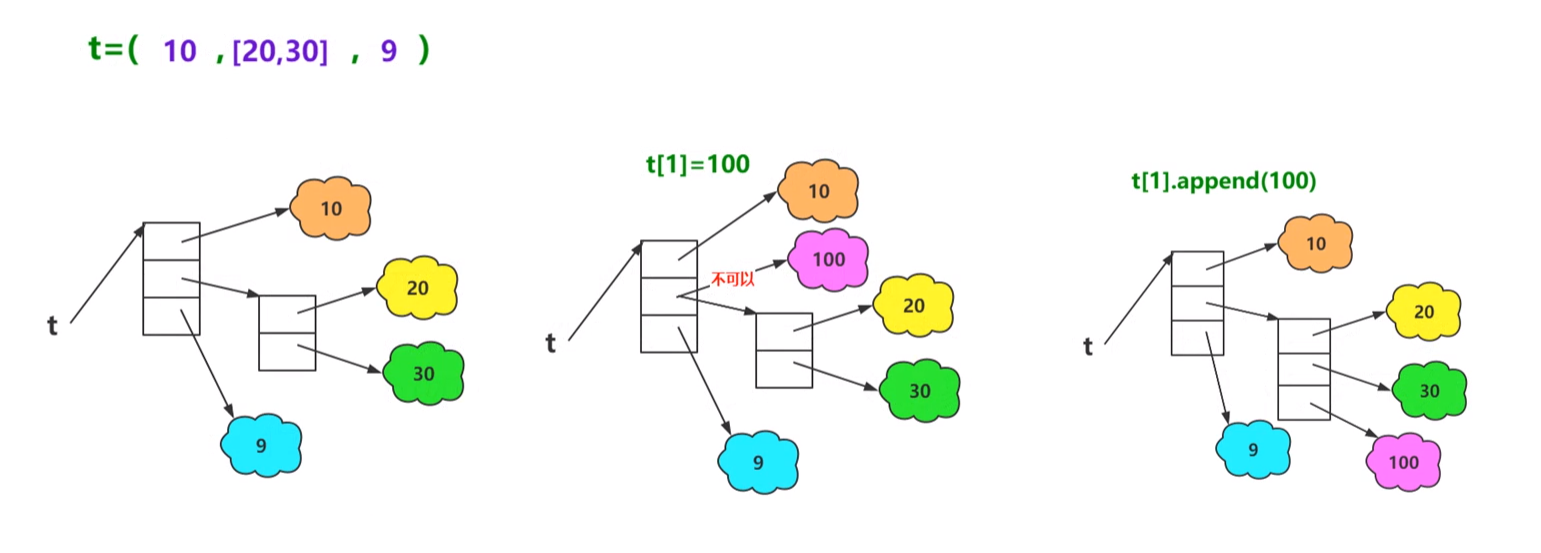
示意代码:
1
2
3
4
5
6
7
8
tuple = (10,[20,30],9)
print(tuple,type(tuple),id(tuple))
print(tuple[0],type(tuple[0]),id(tuple[0]))
print(tuple[1],type(tuple[1]),id(tuple[1]))
print(tuple[2],type(tuple[2]),id(tuple[2]))
tuple[1].append(100)
print(tuple,type(tuple),id(tuple))
tuple[1] = 100
结果:
1
2
3
4
5
6
(10, [20, 30], 9) <class 'tuple'> 2110234151424
10 <class 'int'> 140721863530432
[20, 30] <class 'list'> 2110233841088
9 <class 'int'> 140721863530400
(10, [20, 30, 100], 9) <class 'tuple'> 2110234151424
TypeError: 'tuple' object does not support item assignment
元组是可迭代对象,所以可以使用for…in语句进行遍历。
示例:
1
2
3
tuple = (10,[20,30],9)
for item in tuple:
print(item)
结果:
1
2
3
10
[20, 30]
9
(1)和列表一样,元组支持索引,所以可以使用索引对元组中的元素进行提取。
语法格式:
1
元组名[索引号]
(2)元组是可迭代对象,所以可以用for…in进行遍历。
语法格式:
1
2
for 自定义变量 in 元组名:
操作
(1)集合是Python内置的数据结构,与列表、字典一样都属于可变类型的序列。
(2)集合是没有value的字典,也采用hash表的形式存储数据,也是无序的。
(3)和字典一样,集合使用花括号({ })进行定义。
(4)与字典不同,集合中的元素不可以重复。
(5)示意图:

(1)集合需要使用花括号({ })标示,元素之间使用英文逗号(,)进行分隔。
(2)直接使用花括号进行创建:
1
集合名 = {元素1,元素2,……}
(3)使用内置函数set():
1
集合名 = set(元组内的元素)

- 注意:在创建集合时,如果有重复元素,则重复元素会被自动删去。字符串也可以转换为集合中的元素,各个字符都成为一个元素。定义空集合时,只能使用set()定义,如果使用花括号,则会默认为空字典。
示意代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
s = {1,2,3,4,5,6,7,7,7,8,8,8,9,9,10,'Python','hello','world','Python'} #重复的元素会被自动删去
print(s,type(s))
s1 = set(range(10))
print(s1,type(s1))
s2 = set([1,1,2,3,4,5,6,7,8,9,9,9])
print(s2,type(s2))
s3 = set((1,2133,34,4232))
print(s3,type(s3))
s4 = set('Python')
print(s4,type(s4))
s5 = set({12,3244,112,343,554})
print(s5,type(s5))
s6 = set() #空集合的定义
print(s6,type(s6))
结果:
1
2
3
4
5
6
7
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 'Python', 'hello', 'world'} <class 'set'>
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9} <class 'set'>
{1, 2, 3, 4, 5, 6, 7, 8, 9} <class 'set'>
{4232, 1, 34, 2133} <class 'set'>
{'P', 'y', 'o', 'n', 'h', 't'} <class 'set'>
{112, 343, 554, 3244, 12} <class 'set'>
set() <class 'set'>
(1)集合元素的判断操作
和其他数据结构的判断一样,使用in 或者not in语句,返回值为一个布尔值。
示例 :
1
2
3
4
s = {10,20,30}
print(10 in s)
print(100 in s)
print(100 not in s)
结果:
1
2
3
True
False
True
(2)集合元素的新增
①调用add()方法,一次添加一个元素。
示例:
1
2
3
s = {10,20,30}
s.add(100)
print(s)
结果:
1
{100, 10, 20, 30}
②调用update()方法,一次至少添加一个元素。
示例:
1
2
3
4
5
6
7
s = {10,20,30}
s.update({200,300,400})
print(s)
s.update([123,324234,123212])
print(s)
s.update((6456,655,78))
print(s)
结果:
1
2
3
{400, 20, 200, 10, 300, 30}
{200, 324234, 10, 123212, 400, 20, 30, 300, 123}
{200, 324234, 10, 123212, 78, 655, 400, 20, 30, 300, 6456, 123}
(3)集合元素的删除
①调用remove()方法,一次删除一个指定元素,如果指定元素不存在,则报错为KeyError。
示例:
1
2
3
4
5
s = {10,20,30}
s.remove(10)
print(s)
s.remove(100)
print(s)
结果:
1
2
{20, 30}
KeyError: 100
②调用discard()方法,一次删除一个指定元素,如果指定的元素不存在也不会报错,因此建议使用该方法代替remove()方法进行删除操作。
示例:
1
2
3
4
5
s = {10,20,30}
s.discard(10)
print(s)
s.discard(100)
print(s)
结果:
1
2
{20, 30}
{20, 30}
③调用pop()方法,一次删除一个随机元素,不能指定参数,否则报错。
示例:
1
2
3
4
5
s = {10,20,30}
s.pop()
print(s)
s.pop(10)
print(s)
结果:
1
2
3
{20, 30}
{20, 30}
TypeError: pop() takes no arguments (1 given)
④调用clear()方法,清空集合。
示例:
1
2
3
s = {10,20,30}
s.clear()
print(s,type(s))
结果:
1
set() <class 'set'>
(1)集合间关系的示意图:
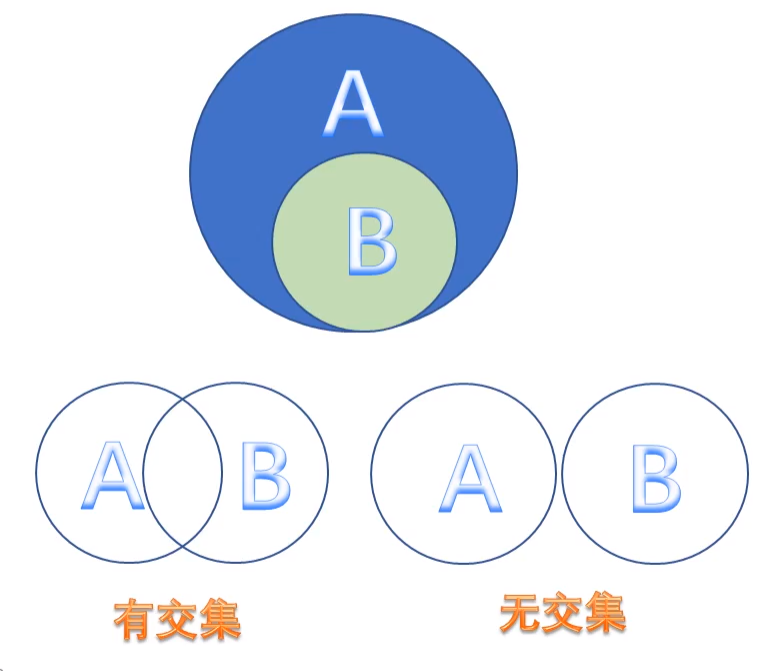
(2)判断两个集合是否相等,可以使用运算符 == 或者 != 进行判断。
示例:
1
2
3
4
s1 = {10,20,30}
s2 = {20,30,10}
print(s1 == s2)
print(s1 != s2)
结果:
1
2
True
False
(3)判断一个集合是否是另一个集合的子集,可以调用issubset()方法进行判断。在上图中,B是A的子集。
示例:
1
2
3
4
5
s1 = {10,20,30,40,50,60}
s2 = {20,30,10}
s3 = {10,20,80}
print(s2.issubset(s1))
print(s3.issubset(s1))
结果:
1
2
True
False
(4)判断一个集合是否是另一个集合的超集,可以调用issuperset()方法进行判断。在上图中, A是B的超集。
示例:
1
2
3
4
5
s1 = {10,20,30,40,50,60}
s2 = {20,30,10}
s3 = {10,20,80}
print(s1.issuperset(s2))
print(s1.issuperset(s3))
结果:
1
2
True
False
(5)判断两个集合是否没有交集,可以调用isdisjoint()方法进行判断。
示例:
1
2
3
4
5
s1 = {10,20,30,40,50,60}
s2 = {20,30,10}
s3 = {90,80,70}
print(s2.isdisjoint(s1))
print(s3.isdisjoint(s1))
结果:
1
2
False
True
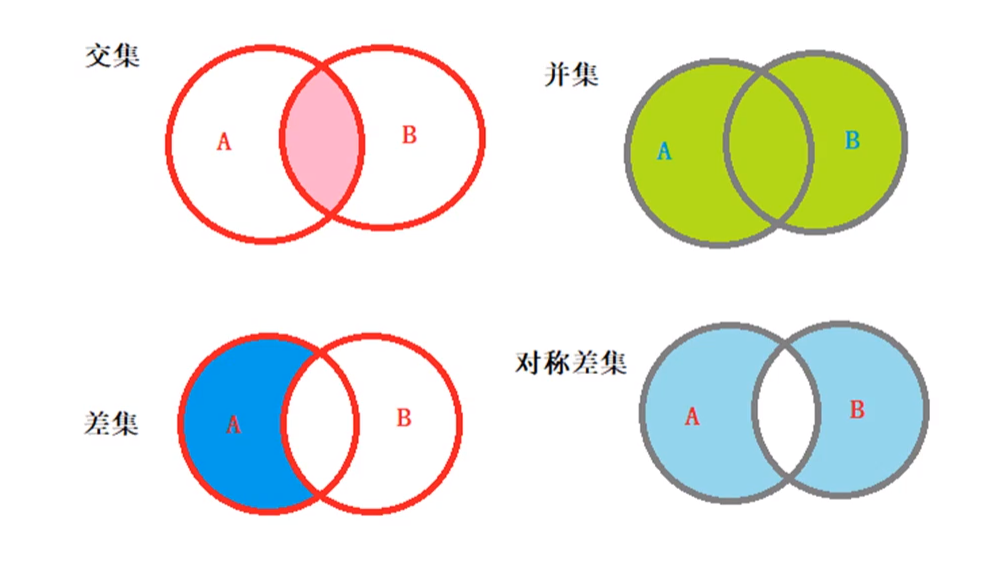
(1)交集:使用intersection()方法或者运算符“&”进行获取。不会使原集合发生变化。
示例:
1
2
3
4
5
6
s1 = {10,20,30,40,50,60}
s2 = {20,30,10}
print(s2.intersection(s1))
print(s2 & s1)
print(s1)
print(s2)
结果:
1
2
3
4
{10, 20, 30}
{10, 20, 30}
{40, 10, 50, 20, 60, 30}
{10, 20, 30}
(2)并集:使用union()方法或者运算符“|”进行获取。不会使原集合发生变化。
示例:
1
2
3
4
5
6
s1 = {10,20,30,40,50,60}
s2 = {20,30,10}
print(s2.union(s1))
print(s2 | s1)
print(s1)
print(s2)
结果:
1
2
3
4
{40, 10, 50, 20, 60, 30}
{40, 10, 50, 20, 60, 30}
{40, 10, 50, 20, 60, 30}
{10, 20, 30}
(3)差集:使用方法difference()或者运算符“-”进行获取。不会使原集合发生变化。
示例:
1
2
3
4
5
6
s1 = {10,20,30,40,50,60}
s2 = {20,30,10}
print(s1.difference(s2))
print(s1 - s2)
print(s1)
print(s2)
结果:
1
2
3
4
{40, 50, 60}
{40, 50, 60}
{40, 10, 50, 20, 60, 30}
{10, 20, 30}
(4)对称差集:使用方法symmetric_difference()或者运算符“^”获取。不会使原集合发生变化。
示例:
1
2
3
4
5
6
s1 = {10,20,30,40,50,60}
s2 = {20,30,10}
print(s2.symmetric_difference(s1))
print(s2 ^ s1)
print(s1)
print(s2)
结果:
1
2
3
4
{50, 40, 60}
{50, 40, 60}
{40, 10, 50, 20, 60, 30}
{10, 20, 30}
(1)定义:用于生成集合的公式。
(2)语法格式:只需把列表生成式中的方括号([ ])替换为花括号({ })即可。
1
集合名 = {表示列表元素的表达式 for 自定义变量 in range(start,stop)}
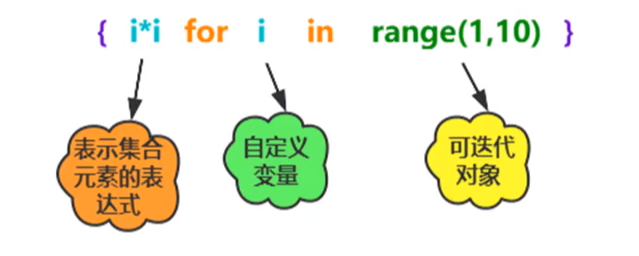
表示集合元素的表达式:集合中所真正包含的元素的值。
自定义变量:需要迭代的变量。
可迭代对象:自定义变量的迭代范围。
注意事项:
“表示集合元素的表达式”中通常包含自定义变量。使用集合生成式时,集合中的对象必须具有一定的规律,可以迭代。
示例:
1
2
s = {i*i for i in range(1,10)}
print(s)
结果:
1
{64, 1, 4, 36, 9, 16, 49, 81, 25}
9.一串连一串——字符串
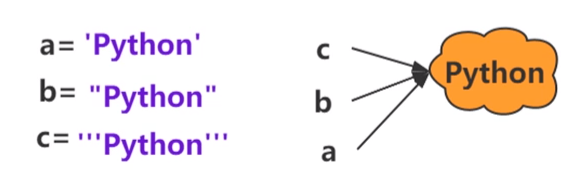
(1)字符串:在Python中字符串是基本数据类型,是一个不可变的字符序列。
(2)什么是字符串的驻留机制
仅保存一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,Python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量。
示意图:
示例代码:
1
2
3
4
5
6
a = 'Python'
b = 'Python'
c = 'Python'
print(a,id(a))
print(b,id(b))
print(c,id(c))
结果:
1
2
3
Python 2756891342128
Python 2756891342128
Python 2756891342128
(3)驻留机制的几种情况(交互模式下,即在Python的交互式命令行下执行)
①字符串的长度为0或1时。
示例:
1
2
3
4
5
6
7
8
9
s1 = ''
s2 = ''
print(s1 is s2)
s1 = '2'
s2 = '2'
print(s1 is s2)
s1 = '200%'
s2 = '200%'
print(s1 is s2)
结果:
1
2
3
True
True
False
②符合标识符格式规定的字符串。
示例:
1
2
3
s1 = 'abc'
s2 = 'abc'
print(s1 is s2)
结果:
1
True
③字符串只在编译时进行驻留,而非运行时。
示例:
1
2
3
4
5
a = 'abc'
b = 'ab'+'c'
c = ''.join(['ab','c'])
print(a is b)
print(a is c)
结果:
1
2
True
False
④[-5,256]之间的整数数字。
示例:
1
2
3
4
5
6
a = -5
b = -5
c = -6
d = -6
print(a is b)
print(c is d)
结果:
1
2
True
False
⑤使用sys中的intern()方法可以强制两个字符串指向同一个对象。
示例:
1
2
3
4
5
6
import sys
a = 'abc%'
b = 'abc%'
print(a is b)
a = sys.intern(b)
print(a is b)
结果:
1
2
True
True
⑥PyCharm对字符串进行了优化处理,原本不驻留的情况在PyCharm中可以驻留。
(4)字符串驻留机制的优缺点
①当需要值相同的字符串时,可以直接从字符串池里面拿来使用,避免频繁的创建和销毁,提升效率并节约内存,因此拼接字符串和修改字符串是比较影响性能的。
②在需要进行字符串拼接时,建议使用str类型的join()方法而非“+”,因为join()方法是先计算出所有字符中的长度,然后再拷贝,只新建一次对象,效率比“+”要高。
(1)查询操作
字符串可以看作特殊的列表,因此也具有索引,可以使用索引的方式对字符串进行操作,返回值也为索引号。
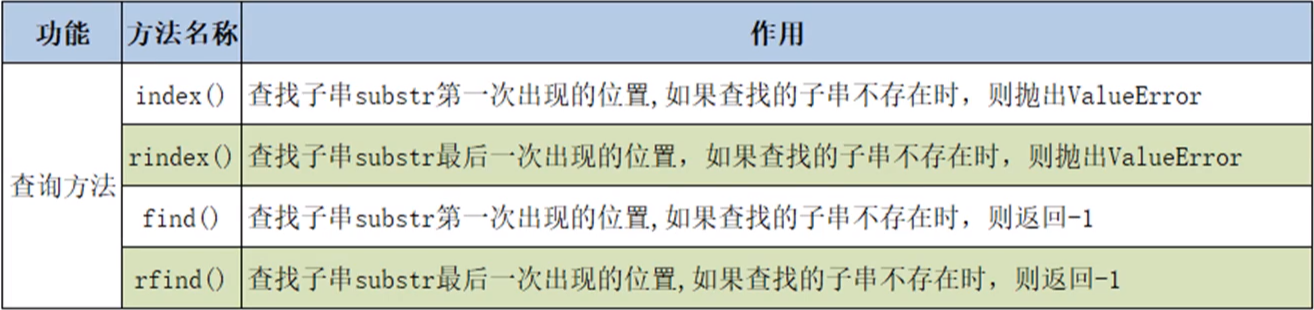
①index():查找指定的子串第一次出现的位置,若不存在则报错为ValueError。
②rindex():查找指定的子串最后一次出现的位置,若不存在则报错为ValueError。
③find():查找指定的子串第一次出现的位置,若不存在则返回-1。
④rfind():查找指定的子串最后一次出现的位置,若不存在则返回-1。
由于方法③④不会报错,因此建议使用这两种方法对字符串进行查询操作。
示例:
1
2
3
4
5
6
7
8
9
str = 'abcdefghijklmn'
print(str.index('a'))
print(str.index('o'))
print(str.rindex('a'))
print(str.rindex('o'))
print(str.find('a'))
print(str.find('o'))
print(str.rfind('a'))
print(str.rfind('o'))
结果:
1
2
3
4
5
6
7
8
0
ValueError: substring not found
0
ValueError: substring not found
0
-1
0
-1
(2)大小写转换操作
由于字符串是不可变对象,所以下列任意一个操作都会生成一个新的字符串对象。
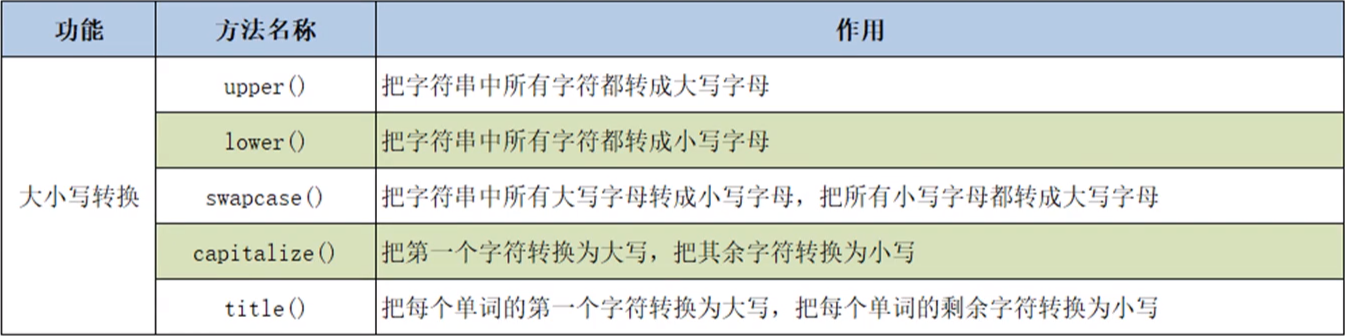
①upper():把字符串中所有字符都转成大写字母。
②lower():把字符串中所有字符都转成小写字母。
③swapcase():把字符串中的所有大写字母转换为小写字母,把所有小写字母转换为大写字母。
④capitalize():把字符串中的第一个字符转换为大写,其余字符转换为小写。
⑤title():把每个单词的第一个字符转换为大写,剩余字符转换为小写。
示例:
1
2
3
4
5
6
7
str = 'Hello,Python'
print(str,id(str))
print(str.upper(),id(str))
print(str.lower(),id(str))
print(str.swapcase(),id(str))
print(str.capitalize(),id(str))
print(str.title(),id(str))
结果:
1
2
3
4
5
6
Hello,Python 2445108333008
HELLO,PYTHON 2445108333008
hello,python 2445108333008
hELLO,pYTHON 2445108333008
Hello,python 2445108333008
Hello,Python 2445108333008
(3)对齐操作
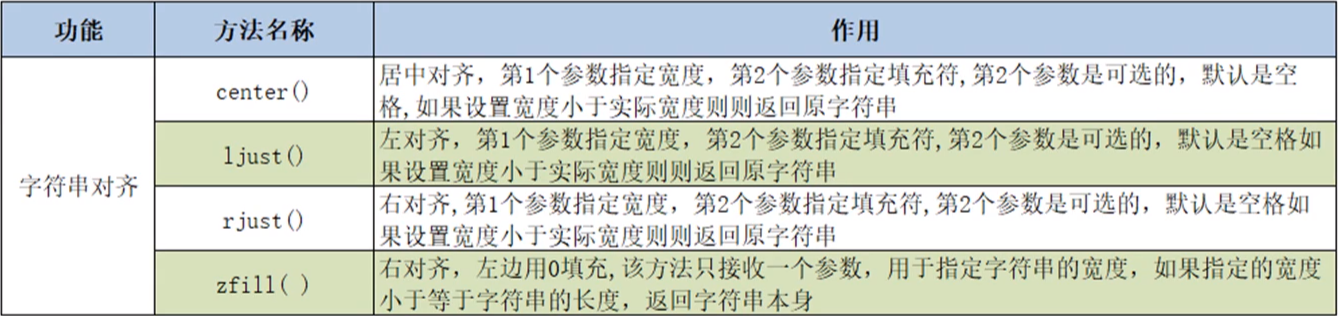
①center():居中对齐,支持两个参数,第一个参数指定宽度,第二个参数指定填充符,第二个参数是可选的,默认是空格,如果设置宽度小于原字符串字符数,则返回原字符串。
②ljust():左对齐,支持两个参数,第一个参数指定宽度,第二个参数指定填充符,第二个参数是可选的,默认是空格,如果设置宽度小于原字符串字符数,则返回原字符串。
③rjust():右对齐,支持两个参数,第一个参数指定宽度,第二个参数指定填充符,第二个参数是可选的,默认是空格,如果设置宽度小于原字符串字符数,则返回原字符串。
④zfill():右对齐,仅支持一个参数,默认的填充符为0,参数用于指定宽度,如果设置宽度小于原字符串字符数,则返回原字符串。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
str = 'Hello,Python'
print(str.center(20,'*'))
print(str.center(20))
print(str.center(10))
print(str.ljust(20,'*'))
print(str.ljust(20))
print(str.ljust(10))
print(str.rjust(20,'*'))
print(str.rjust(20))
print(str.rjust(10))
print(str.zfill(20))
print(str.zfill(10))
结果:
1
2
3
4
5
6
7
8
9
10
11
****Hello,Python****
Hello,Python
Hello,Python
Hello,Python********
Hello,Python
Hello,Python
********Hello,Python
Hello,Python
Hello,Python
00000000Hello,Python
Hello,Python
(4)劈分操作
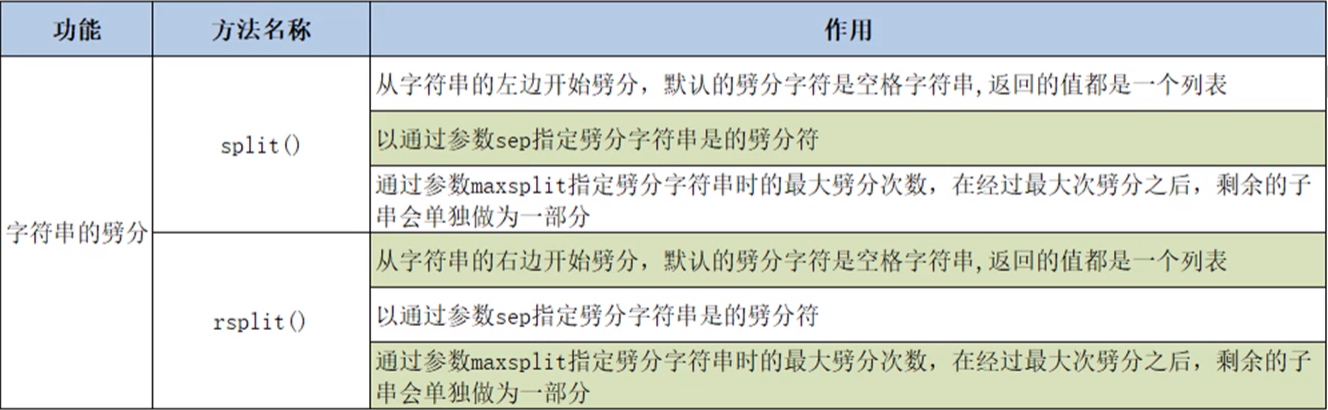
①split():从字符串的左边开始劈分,默认的劈分字符是空格字符串,返回值为一个列表。可以通过参数sep指定劈分字符串的劈分符,参数maxsplit指定劈分字符串时最大的劈分次数,在经过最大次数的劈分之后,剩余的子串会单独作为一部分。
②rsplit():从字符串的右边开始劈分,默认的劈分字符是空格字符串,返回值为一个列表。可以通过参数sep指定劈分字符串的劈分符,参数maxsplit指定劈分字符串时最大的劈分次数,在经过最大次数的劈分之后,剩余的子串会单独作为一部分。
示例:
1
2
3
4
5
6
7
8
9
10
str1 = 'Hello World Python'
list1 = str1.split()
print(list1)
str2 = 'Hello|World|Python'
print(str2.split(sep = '|'))
print(str2.split(sep = '|',maxsplit = 1))
list2 = str2.rsplit()
print(list2)
print(str2.rsplit(sep = '|'))
print(str2.rsplit(sep = '|',maxsplit = 1))
结果:
1
2
3
4
5
6
['Hello', 'World', 'Python']
['Hello', 'World', 'Python']
['Hello', 'World|Python']
['Hello|World|Python']
['Hello', 'World', 'Python']
['Hello|World', 'Python']
(5)判断字符串
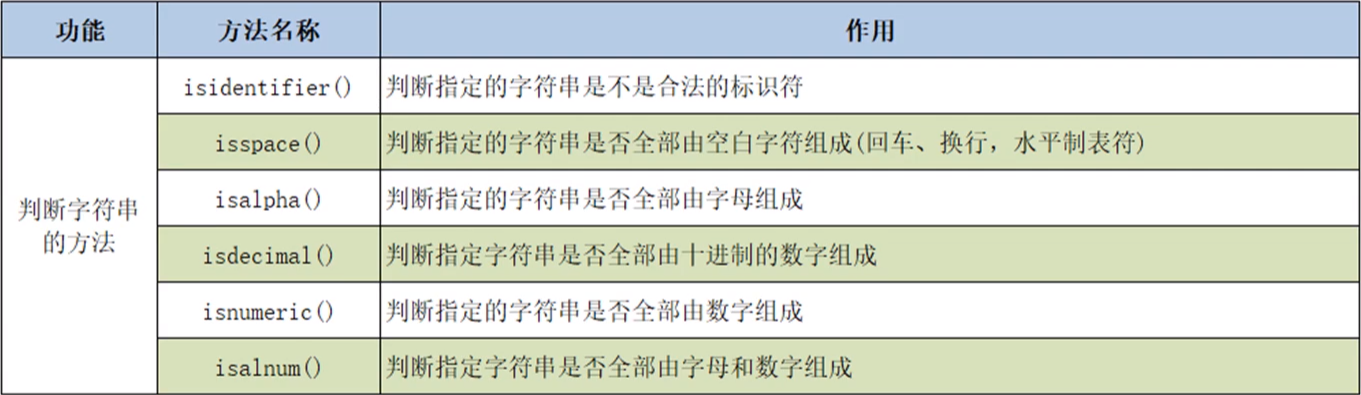
①isidentifier():判断指定的字符串是否为合法的标识符。
②isspace():判断制定的字符串是否全部由空白字符(回车、换行、水平制表符)组成。
③isalpha():判断指定的字符串是否全部由字母组成。
④isdecimal():判断指定字符串是否全部由十进制数字组成。
⑤isnumeric():判断指定的字符串是否全部由数字组成。
⑥isalnum():判断指定字符串是否全部由字母和数字组成。
- 注意:汉字在判断过程中也被视为字母。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
s1 = 'HelloWorldPython'
s2 ='abc%'
print(str1.isidentifier())
print(s2.isidentifier())
print('\t'.isspace())
print('abc'.isalpha())
print('abc1'.isalpha())
print('张三'.isalpha())
print('123'.isdecimal())
print('123四'.isdecimal())
print('123'.isnumeric())
print('123四'.isnumeric())
print('I II III IV'.isnumeric())
print('abc123'.isalnum())
print('123张三'.isalnum())
print('123!'.isalnum())
结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
False
False
True
True
False
True
True
False
True
True
False
True
True
False
(5)字符串操作的其他方法

①replace():替换字符串,支持三个参数,第一个参数指定被替换的子串,第二个参数指定替换字串的字符串,第三个参数指定最大替换次数,该方法返回替换后得到的字符串,替换前的字符串不发生变化。
②join():合并字符串,将已有字符串和另一个字符串或者列表或元组中的字符串合并成一个字符串,需要在其后的括号中注明需要合并字符串的列表或元组对象。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
s1 = 'Hello Python'
print(s1.replace('Python','Java'))
s2 = 'Hello Python Python Python'
print(s2.replace('Python','Java',2))
list = ['hello','world','Python']
print('|'.join(list))
print(''.join(list))
t = ('hello','world','Python')
print(''.join(t))
print('*'.join('Python')) #此时后面的Python作为字符串序列被“*”连接
结果:
1
2
3
4
5
6
Hello Java
Hello Java Java Python
hello|world|Python
helloworldPython
helloworldPython
P*y*t*h*o*n
(1)运算符:>,>=,<,<=,==,!=
(2)比较规则:首先比较两个字符串中的第一个字符,如果相等则继续比较下一个字符,依次比较下去,直到两个字符串中的字符不相等时,其比较结果就是两个字符串的比较结果,两个字符串中的所有后续字符将不再被比较。
(3)比较原理:两个字符进行比较时,比较的是其ordinal value(原始值,也即其在ASCII码表中对应的数值),调用内置函数ord()可以得到指定字符的原始值,与内置函数ord()对应的是内置函数chr(),调用内置函数chr()时指定原始值可得到其对应的字符。
示例:
1
2
3
4
print('apple'>'app')
print('apple'>'banana')
print(ord(a),ord(b))
print(chr(97),chr(98))
结果:
1
2
3
4
True
False
97 98
a b
(1)字符串是不可变对象,不具备增删改操作,但是它也具备索引,切片操作将产生新的对象。
(2)字符串在合并之后,将具备新的索引。
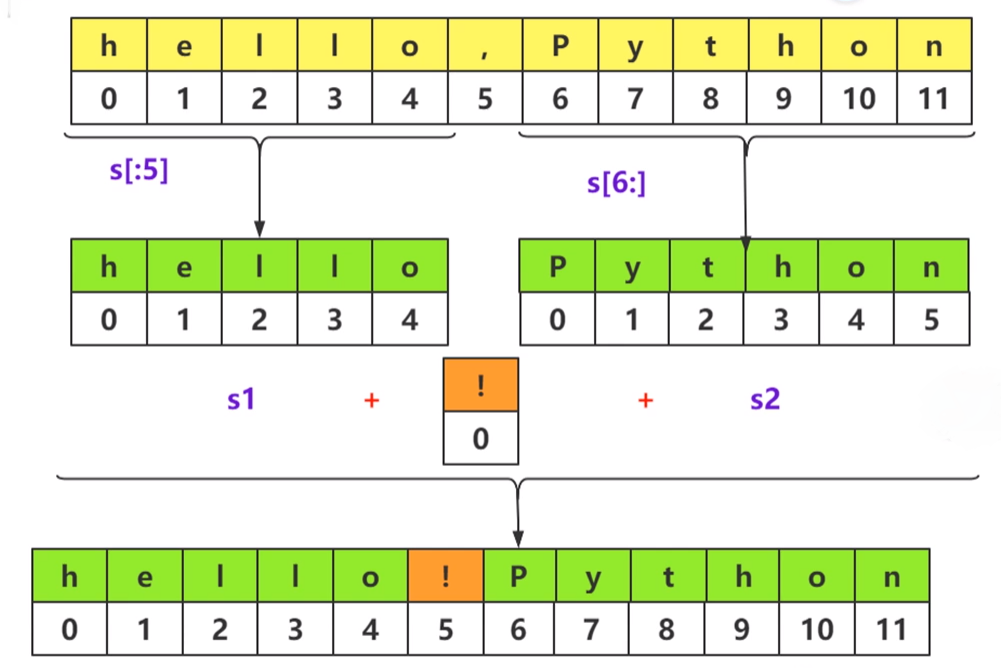
示例:
1
2
3
4
5
6
7
8
9
10
11
12
s = 'hello,Python'
s1 = s[:5]
s2 = s[6:]
s3 ='!'
newstr = s1+s3+s2
print(s1)
print(s2)
print(newstr)
print(s[1:5:1])
print(s[::2])
print(s[::-1])
print(s[-6::1])
结果:
1
2
3
4
5
6
7
hello
Python
hello!Python
ello
hloPto
nohtyP,olleh
Python
(1)为什么需要格式化字符串:节约空间和算力。
(2)格式化字符串的方式:
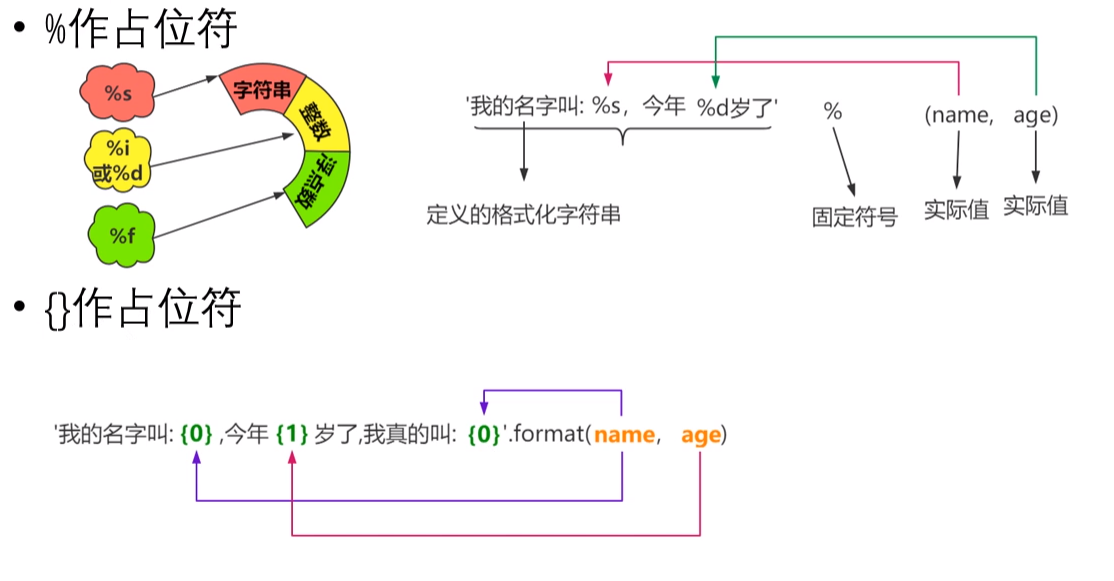
①%:“%s”为字符串的占位符,“%d”或“%i”为整数的占位符,“%f”为浮点数的占位符。
②{ }:需要和format()函数一起使用。
③f-string(f-字符串):格式为f'字符串',用于标示格式化字符串,字符串后可以不用再加上“.format()”的格式。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
name = '张三'
age = 20
print('我叫%s,今年%d岁' % (name,age))
print('我叫{0},今年{1}岁'.format(name,age))
print(f'我叫{name},今年{age}岁')
#指定字符串宽度以及精度
print('%10d' % 99) #10表示字符串总宽度
print('%.3f' % 3.141592654) #.3表示小数位数为3位
print('%10.3f' % 3.141592654) #同时表示宽度和精度
print('{0:.3}'.format(3.141592654)) #0表示占位符序号,也可不写,3表示一共3位数字
print('{:.3f}'.format(3.141592654)) #3f表示3位小数
print('{:10.3f}'.format(3.141592654)) #同时表示宽度和精度
结果:
1
2
3
4
5
6
7
8
9
我叫张三,今年20岁
我叫张三,今年20岁
我叫张三,今年20岁
99
3.142
3.142
3.14
3.142
3.142
(1)流程示意图
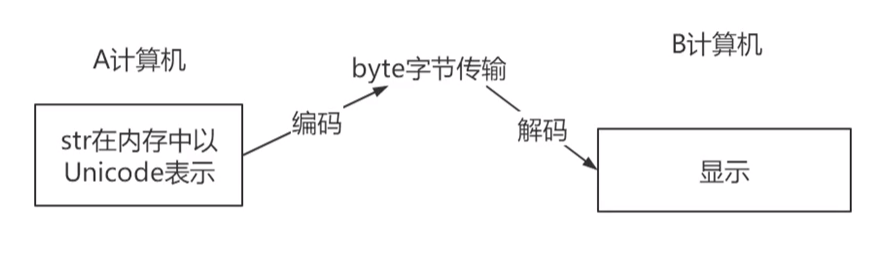
(2)编码与解码
①编码:使用encode()方法,将字符串转化为二进制数据(bytes)。参数为encoding='编码格式'。
②解码:使用decode()方法,将二进制bytes类型的数据转化为字符串类型。参数为encoding='编码格式',解码格式要和编码格式相同,否则报错。
示例:
1
2
3
4
5
6
7
8
9
10
11
s = '天涯共此时'
#编码
print(s.encode(encoding = 'GBK'))
print(s.encode(encoding = 'UTF-8'))
#解码
byte = s.encode(encoding = 'GBK')
print(byte.decode(encoding = 'GBK'))
print(byte.decode(encoding = 'UTF-8'))
byte = s.encode(encoding = 'UTF-8')
print(byte.decode(encoding = 'UTF-8'))
print(byte.decode(encoding = 'GBK'))
结果:
1
2
3
4
5
6
b'\xcc\xec\xd1\xc4\xb9\xb2\xb4\xcb\xca\xb1'
b'\xe5\xa4\xa9\xe6\xb6\xaf\xe5\x85\xb1\xe6\xad\xa4\xe6\x97\xb6'
天涯共此时
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xcc in position 0: invalid continuation byte
天涯共此时
UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 10: illegal multibyte sequence
10.水晶球不调用不动——函数
(1)函数的定义:函数就是执行特定任务完成特定功能的一段代码。
(2)函数的必要性
①可以复用代码,提高代码利用率;
②可以隐藏实现细节;
③提高代码可维护性;
④提高代码可读性以便调试。
(3)函数的创建
语法格式:
1
2
3
def 函数名([输入参数]):
函数体
[return 返回值]
- 注意:函数名需要符合标识符的命名规范。
(4)函数的调用
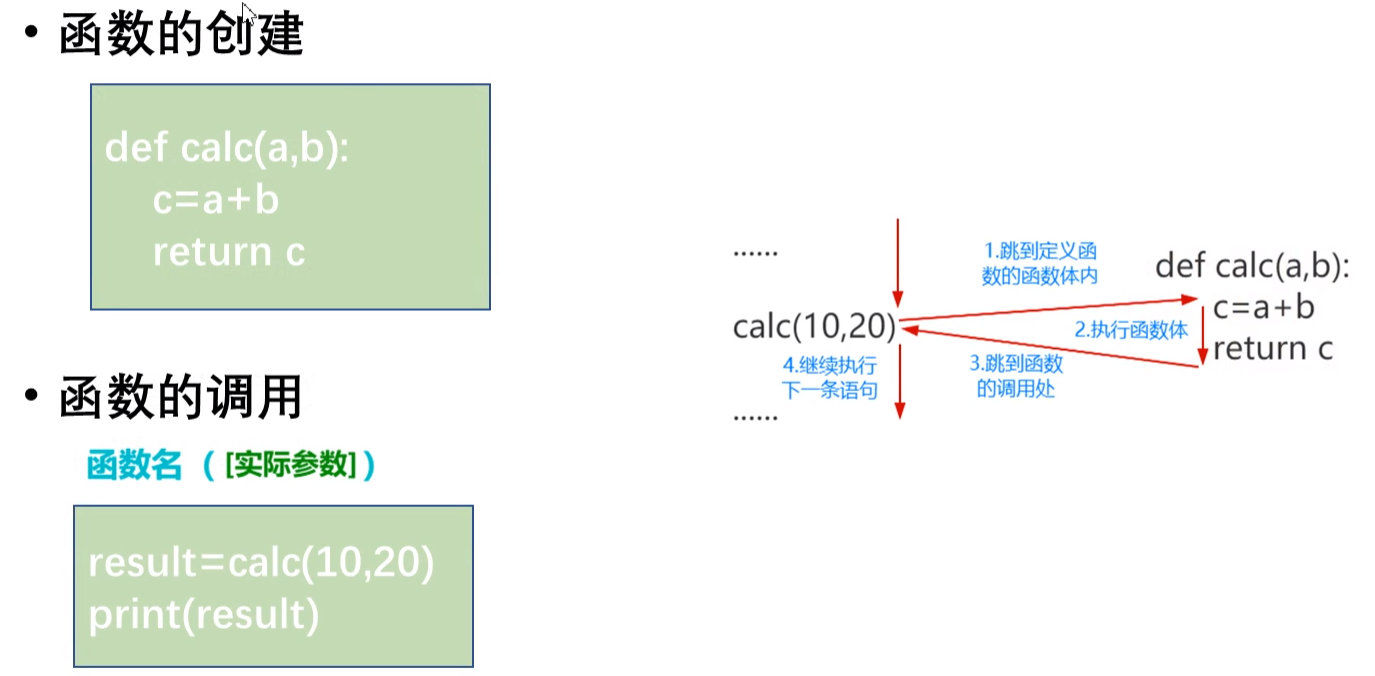
示例:
1
2
3
4
5
def calc(a,b): #a,b称为形式参数,简称形参,形参的位置在函数的定义处
c = a + b
return c
result = calc(10,20) #10,20为实际参数的值,简称实参,实参的位置在函数的调用处
print(result)
结果:
1
30
(1)参数类型
①形式参数,简称形参,形参的位置在函数的定义处。
②实际参数,简称实参,实参的位置在函数的调用处。
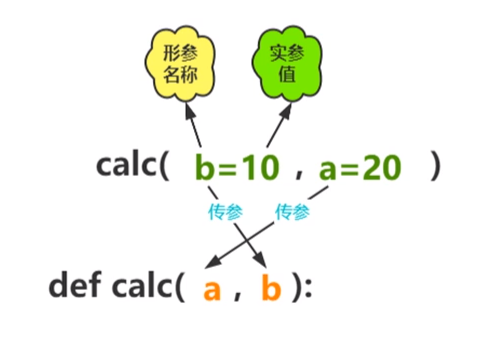
(2)函数调用的参数传递
①位置实参:根据形参对应的位置进行实参传递。

②关键字实参:根据形参名称进行实参传递,等号左侧的变量名称称为关键字参数。
(2)函数调用时参数传递后可变对象与不可变对象的变化
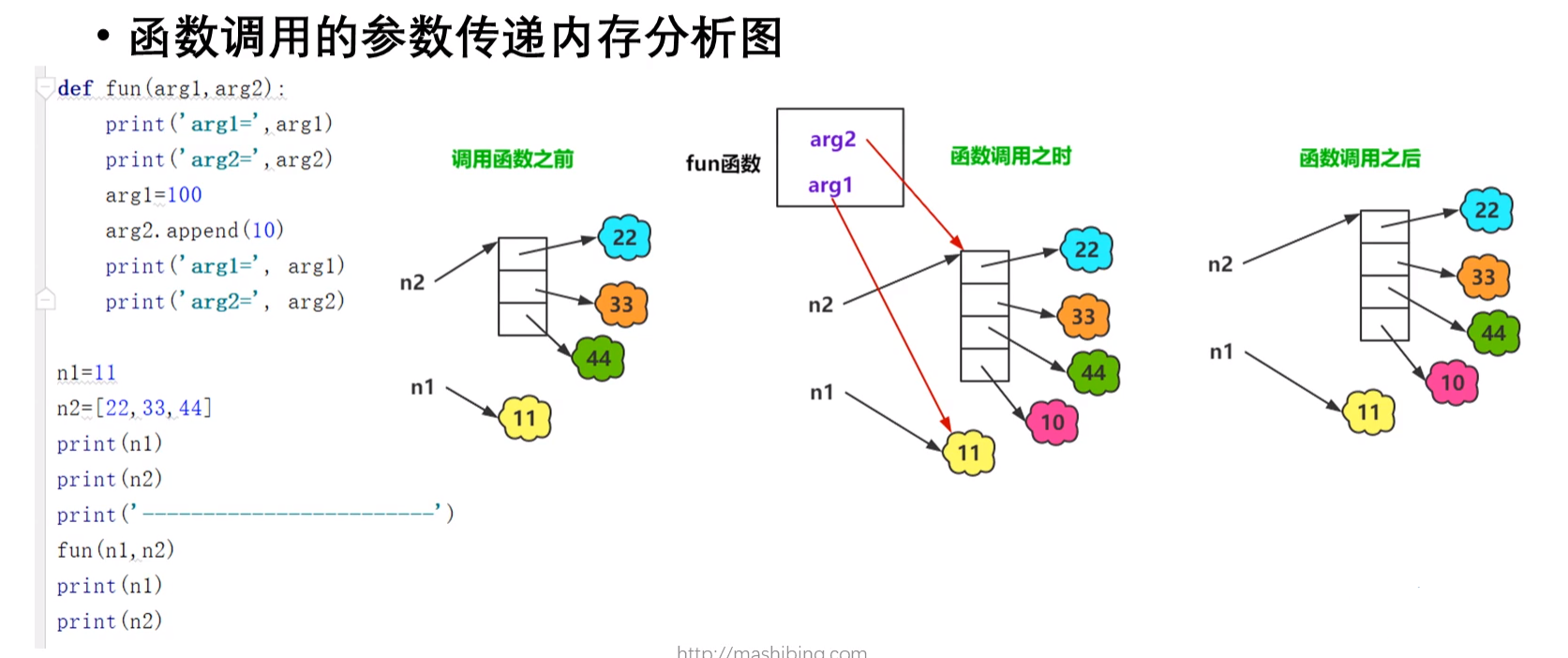
- 注意:传参时,形式参数的名称和实际参数的名称可以不同。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def fun(arg1,arg2):
print('arg1:',arg1)
print('arg2:',arg2)
arg1 = 100
arg2.append(10)
print('arg1:',arg1)
print('arg2:',arg2)
n1 = 11
n2 = [22,33,44]
print('n1:',n1)
print('n2:',n2)
fun(n1,n2) #位置传参:arg1,arg2是函数定义处的形参,n1,n2是函数调用处的实参,因此位置传参时实参名称可以与形参名称不一致
print('n1:',n1)
print('n2:',n2)
结果:
1
2
3
4
5
6
7
8
n1: 11
n2: [22, 33, 44]
arg1: 11
arg2: [22, 33, 44]
arg1: 100
arg2: [22, 33, 44, 10]
n1: 11
n2: [22, 33, 44, 10]
总结:在函数调用传参过程中,如果是不可变对shili象,在函数体的修改过程中不会影响实参的值;如果是可变对象,在函数体的修改过程中会影响实参的值。
函数的返回值
函数在定义时,是否需要返回值,视情况而定。
(1)如果函数没有返回值(函数执行完毕后,不需要给调用处提供数据),return可以省略不写。
(2)如果函数有唯一的返回值,则直接返回相应类型的返回值。
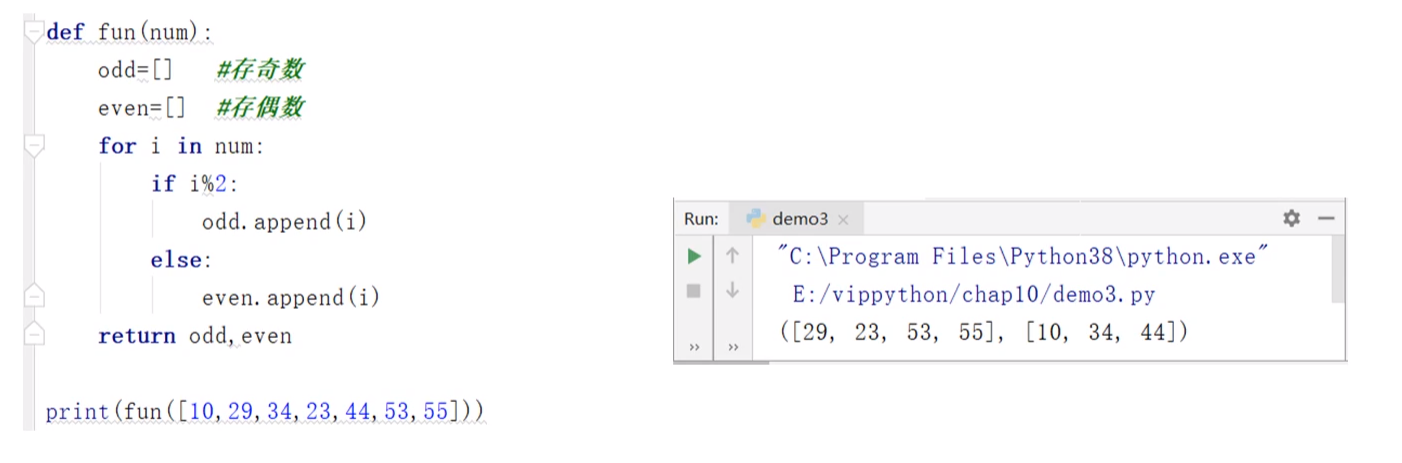
(3)函数返回多个值时,结果为元组。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#函数不存在返回值
def fun1():
print('hello')
fun1()
#函数有唯一返回值
def fun2():
return 'hello'
res = fun2()
print(res)
#函数存在多个返回值
def fun(num):
odd = [] #存奇数
even = [] #存偶数
for i in num:
if i%2: #此处利用了对象的布尔值——0为False,非0为True
odd.append(i)
else:
even.append(i)
return odd,even
print(fun([10,29,34,23,44,53,55]))
结果:
1
2
3
hello
hello
([29, 23, 53, 55], [10, 34, 44])
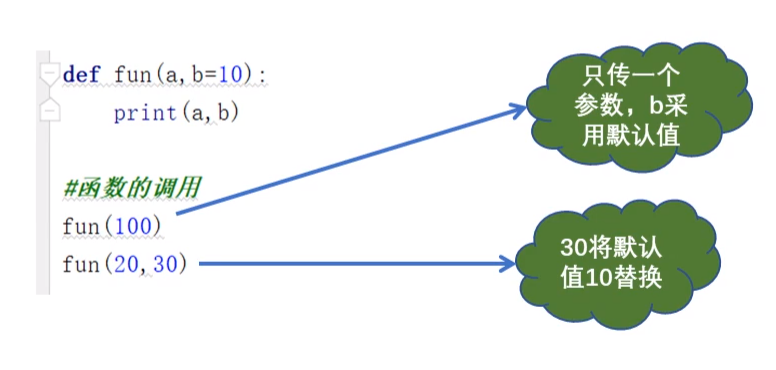
(1)函数定义时,给形参设置默认值,只有与默认值不符的时候才需要传递实参。
示例:
1
2
3
4
5
def fun(a,b=10):
print(a,b)
fun(100)
fun(20,30)
结果:
1
2
100 10
20 30
同样地,对于print()函数,其也具有默认值参数,即输出的尾端,默认为“\n”换行符,但是可以使用“end=’‘”语句进行默认值的替换。
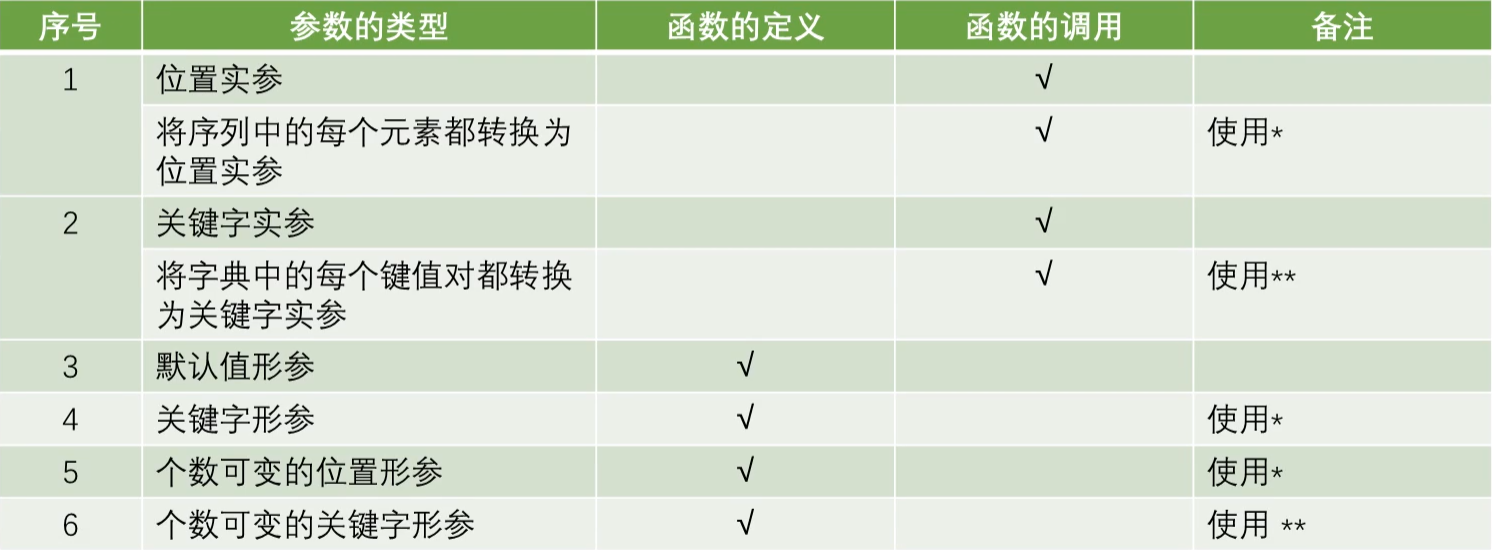
(2)个数可变的位置参数
①定义函数时,可能无法事先确定传递的位置实参个数时,使用个数可变的位置参数。
②使用“*”定义个数可变的位置形参。
③定义的结果为一个元组。
④同时定义的个数可变的位置参数只能有1个。

示例:
1
2
3
4
5
6
def fun(*args):
print(args)
fun(10)
fun(10,30)
fun(30,40,50)
结果:
1
2
3
(10,)
(10, 30)
(30, 40, 50)
(3)个数可变的关键字参数
①定义函数时,无法事先确定传递的关键字实参的个数时,使用个数可变的关键字形参。
②使用“**”定义个数可变的关键字参数。
③定义的结果为一个字典。
④同时定义的个数可变的关键字参数只能有1个。
⑤在一个函数的定义过程中,既有个数可变的位置参数又有个数可变的关键字参数时,要求个数可变的位置参数放在个数可变的关键字参数之前,否则程序报错。
⑥在定义参数时,如果有多个参数,从“*”之后的参数只能使用关键字参数方式进行传参。

示例:
1
2
3
4
5
6
def fun(**args):
print(args)
fun(a=10)
fun(a=10,b=30)
fun(a=30,b=40,c=50)
结果:
1
2
3
{'a': 10}
{'a': 10, 'b': 30}
{'a': 30, 'b': 40, 'c': 50}
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#序列的传参
def fun(a,b,c):
print('a=',a)
print('b=',b)
print('c=',c)
fun(10,20,30)
list = [11,22,33]
fun(list)
fun(*list)
#字典的传参
def fun(a,b,*,c,d): #从“*”之后的参数只能使用关键字参数方式进行传参
print('a=',a)
print('b=',b)
print('c=',c)
print('d=',d)
fun(10,20,30,40)
fun(10,20,c=30,d=40)
fun(a=10,b=20,c=30,d=40)
dict = {'a':10,'b':20,'c':30,'d':40,'e':50} #传参个数不可以多于形参个数,否则报错
dict = {'a':10,'b':20,'c':30,'d':40}
fun(dict)
fun(**dict)
结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
a= 10
b= 20
c= 30
TypeError: fun() missing 2 required positional arguments: 'b' and 'c'
a= 11
b= 22
c= 33
TypeError: fun() takes 2 positional arguments but 4 were given
a= 10
b= 20
c= 30
d= 40
a= 10
b= 20
c= 30
d= 40
TypeError: fun() missing 3 required positional arguments: 'b', 'c', and 'd'
TypeError: fun() got an unexpected keyword argument 'e'
a= 10
b= 20
c= 30
d= 40
(1)定义:程序代码能访问该变量的区域。
(2)分类:根据变量的有效范围,可以分为如下两类:
①局部变量:在函数内定义并使用的变量,只在函数内部有效,局部变量使用“global”声明,这个变量就会成为全局变量。
②全局变量:在函数体外定义的变量,可作用于函数内外。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#局部变量
def fun1(a,b):
c=a+b
print(c)
print(a)
print(b)
#函数体外定义的全局变量
name ='杨老师'
print(name)
def fun2():
print(name)
fun2()
#函数体内定义的全局变量
def fun3():
global age
age = 20
print(age)
fun3()
print(age)
结果:
1
2
3
4
5
6
NameError: name 'a' is not defined #参数a的调用范围超过了其作用域,程序报错
NameError: name 'b' is not defined #参数b的调用范围超过了其作用域,程序报错
杨老师
杨老师 #name为全局变量,在函数内外均可调用
20
20
(1)定义:如果在一个函数的函数体内使用了该函数本身,则这个函数就称为递归函数。
(2)组成部分:递归调用与递归终止条件,因此必须使用if…else语法结构。
(3)调用过程:每递归调用一次函数,都会在栈内存分配一个栈帧;每执行完一次函数,都会释放相应的空间。
(4)递归的优缺点:
①优点:占用内存多,效率低下。
②缺点:思路和代码简单。
示例1:使用递归计算阶乘
1
2
3
4
5
6
7
8
9
def fac(n):
if n==1:
return 1 #递归终止条件
else:
res = n*fac(n-1)
print(res)
return res
print(fac(6))
结果:
1
2
3
4
5
6
2
6
24
120
720
720
代码执行过程分析图:
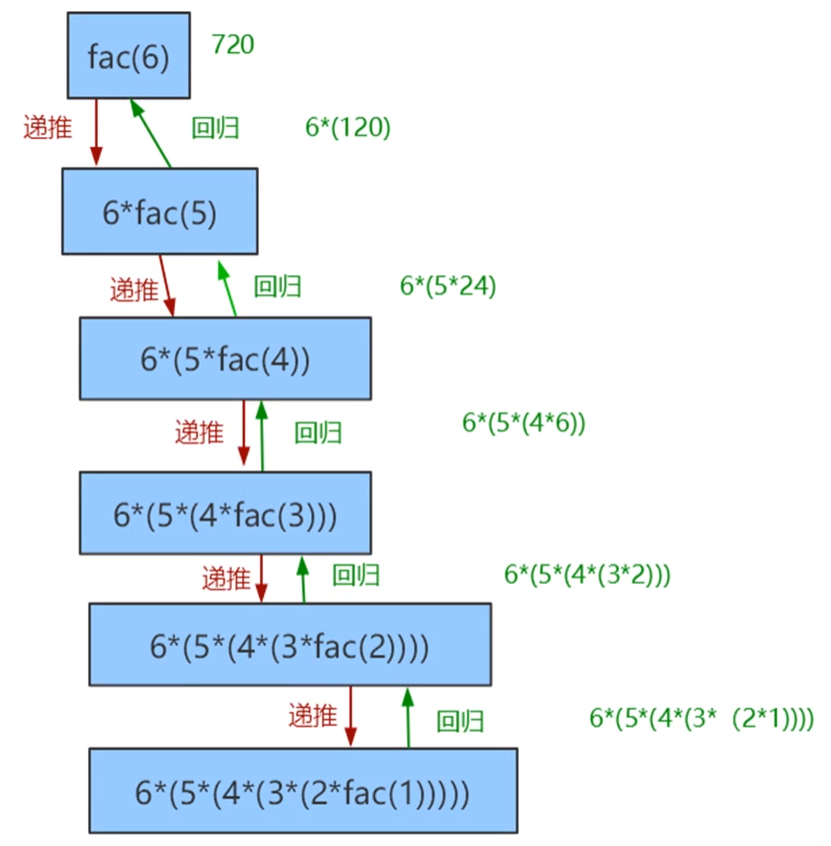
代码执行过程分析:
①传递参数n=6,进入fac()函数体;
②n!=1,执行else后的语句,二次调用fac()函数,此时传递参数n-1,结果为5;
③重复②步骤直至传递参数n-1的值为1,执行if后的语句,返回值1;
④执行上一次fac()函数调用中的else部分,计算res的值,并依次输出,依次为2×1,3×2,4×6,5×24,6×120;
⑤输出最终res的值即为阶乘结果。
示例2:使用递归输出斐波那契数列
1
2
3
4
5
6
7
8
9
10
11
def fib(n):
if n==1:
return 1
elif n==2:
return 1
else:
return fib(n-1)+fib(n-2)
print(fib(6))
for i in range(1,7):
print(fib(i),end='\t')
结果:
1
2
8
1 1 2 3 5 8
11.全民来找茬——异常及其调试
(1)由来:世界上第一步万用计算机的进化版——马克二号(Mark Ⅱ)。
(2)BUG的常见类型
①粗心导致的语法错误:SyntaxError


②知识点不熟练导致的错误

③思路不清晰导致的问题
常用解决方案:
Ⅰ.使用print()函数打印输出可能出现异常的段内部处理的值以检查是否出错;
Ⅱ.使用”#“暂时注释出错的代码使得程序得以运行并继续排查出错段以下的错误.



④被动性BUG:来自用户或者某些极端特殊情况
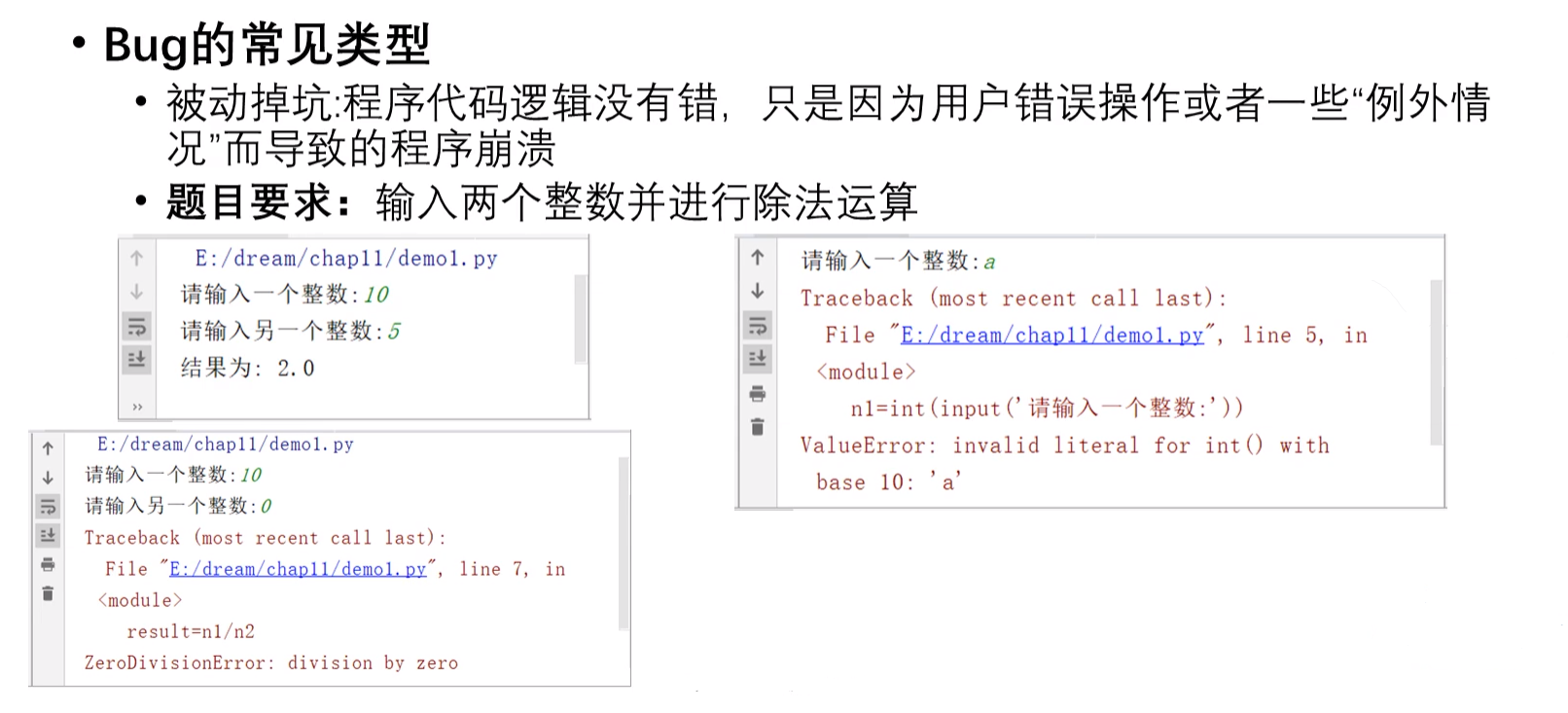
(3)DEBUG的常用检查点
①是否遗漏了末尾的冒号,如if语句、循环语句、else子句等;
②是否有缩进错误,该缩进的没有缩进,不该缩进的缩进了;
③是否把英文符号写成中文符号;
④在字符串拼接时是否把字母和数字拼接在了一起;
⑤变量是否定义了如while循环条件的变量;
⑥是否把“==”比较运算符与“=”赋值运算符混用;
⑦在使用带索引的数据结构时,索引是否越界;
⑧在使用带限制性的方法时,例如append()等时,使用是否规范。
(4)Python的异常处理机制
Python的异常处理机制可以在代码执行时将出现的错误内部消化,从而使得程序继续运行而不是中止报错。
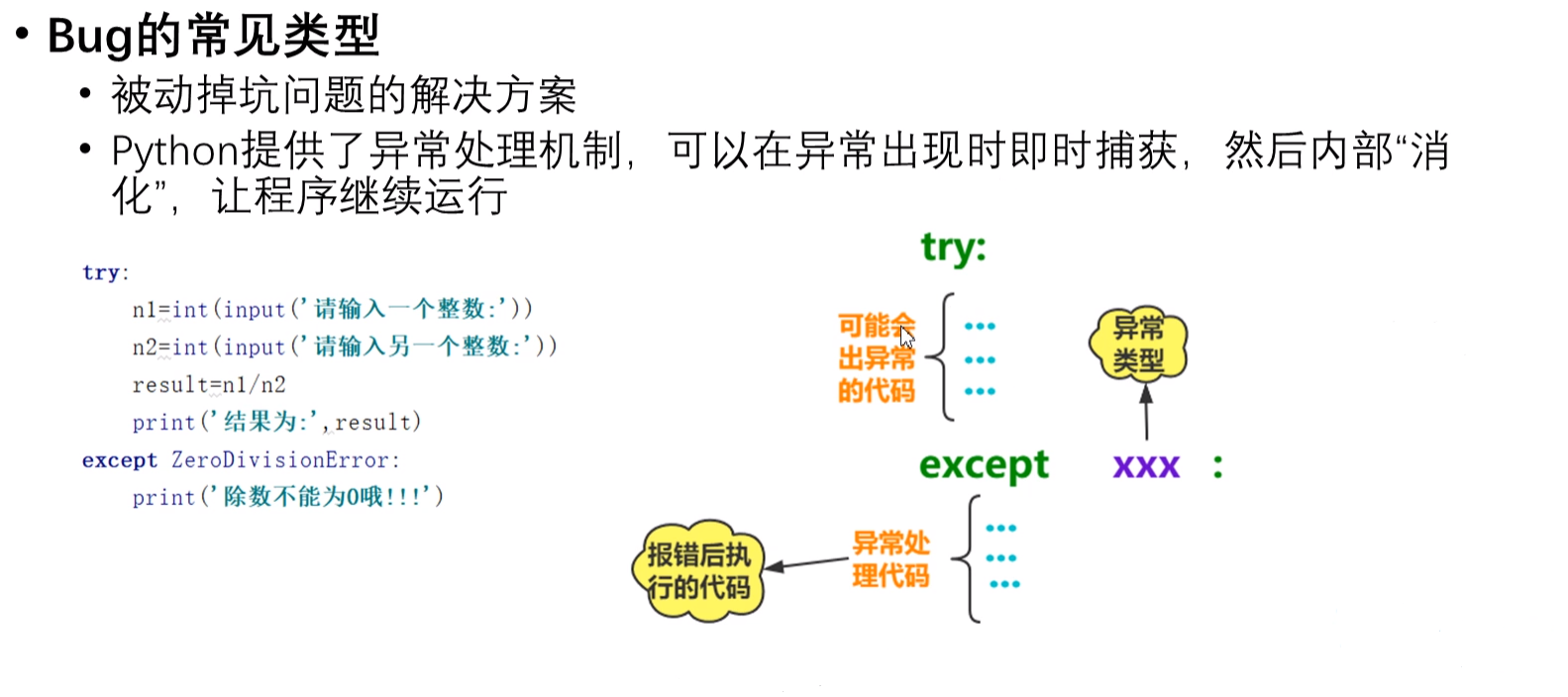
①try-exception语法
使用“try:”标示可能出现异常的代码,然后使用“except 异常类型:”标示异常出现后要转执行的代码。BaseException是最大的一类异常类型,用于标示所有的异常,可以用于防止except情况的遗漏。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
try:
a = int(input('请输入第一个整数:'))
b = int(input('请输入第二个整数:'))
result = a/b
print('结果为:',result)
except ZeroDivisionError:
print('除数不能为0!')
except ValueError:
print('只能输入整数!')
except BaseException as e:
print('程序执行异常!错误类型:',e)
print('程序结束')
输入:
1
2
10
0
结果:
1
2
3
4
请输入第一个整数:10
请输入第二个整数:0
除数不能为0!
程序结束

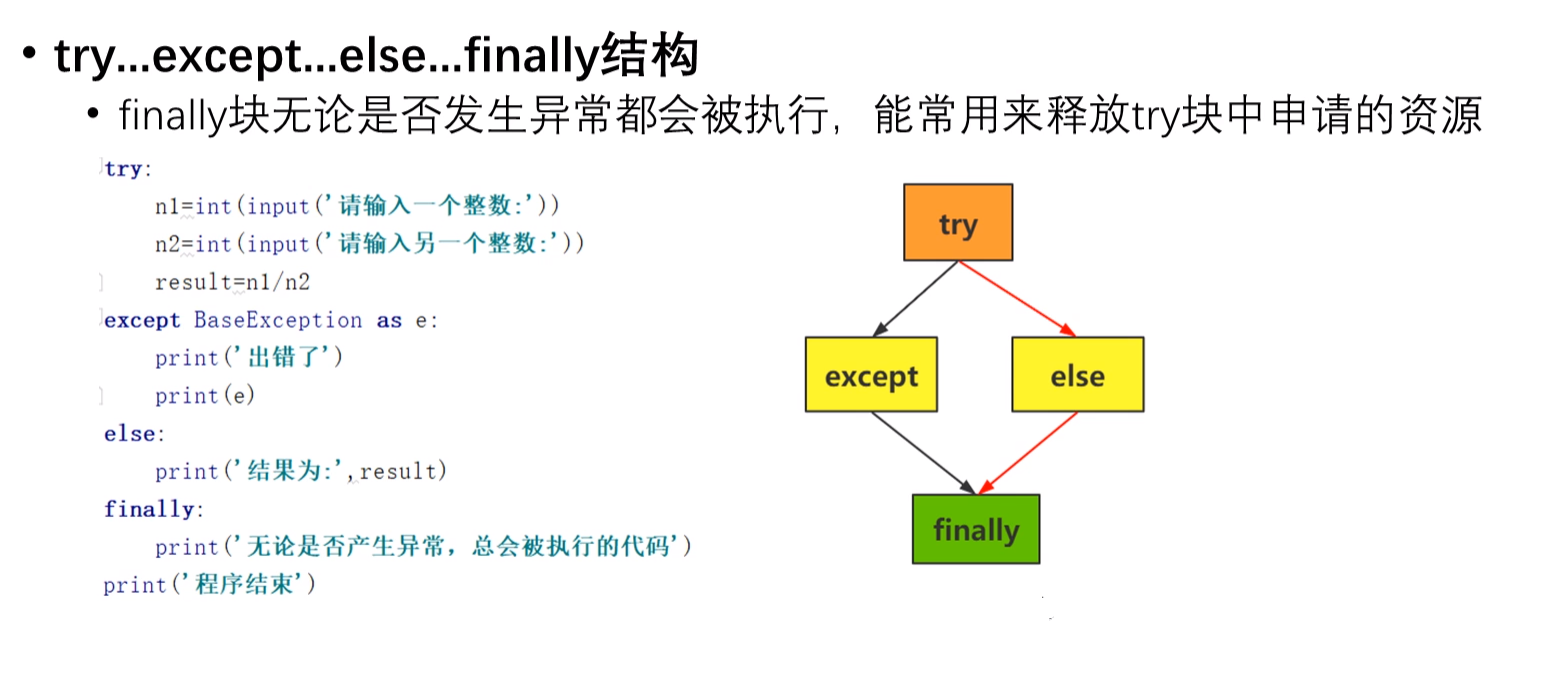
②try-except-else-finally语法
只有当except后所有的错误类型均不发生时,才执行else后的内容。但是无论执行了except还是else后的内容,finally后的内容一定会被执行,并且释放try块申请的资源。
示例:
1
2
3
4
5
6
7
8
9
10
try:
a = int(input('请输入第一个整数:'))
b = int(input('请输入第二个整数:'))
result = a/b
except BaseException as e:
print('程序执行异常!错误类型:',e)
else:
print('结果为:',result)
finally:
print('程序结束')
输入:
1
2
10
0
结果:
1
2
3
4
请输入第一个整数:10
请输入第二个整数:0
程序执行异常!错误类型: division by zero
程序结束

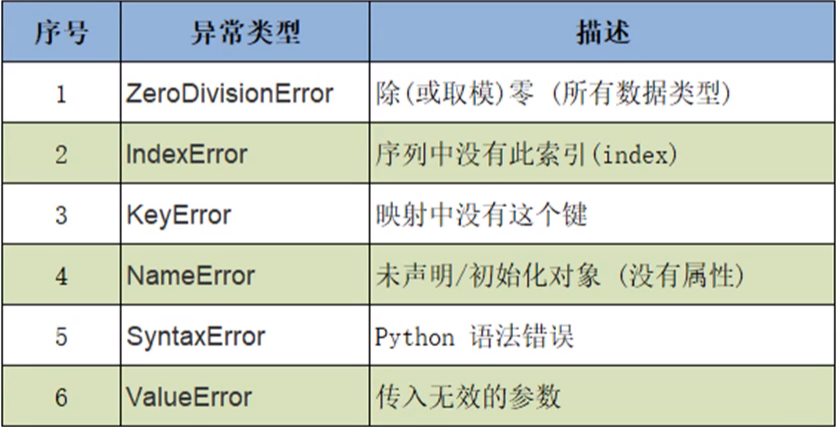
③Python中的常见异常类型
④异常处理模块:traceback
可以将程序运行过程中出现的异常记录下来,可以存入日志文件(log)中。
示例:
1
2
3
4
5
6
7
8
import traceback
try:
print('---------------------------------------')
a = int(input('请输入第一个整数:'))
b = int(input('请输入第二个整数:'))
result = a/b
except:
traceback.print_exc()
输入:
1
2
10
0
结果:
1
2
3
4
5
6
7
---------------------------------------
请输入第一个整数:10
请输入第二个整数:0
Traceback (most recent call last):
File "E:/Python程序设计学习/Python基础语法/BUG,异常与调试.py", line 28, in <module>
result = a/b
ZeroDivisionError: division by zero

(5)PyCharm的异常处理机制
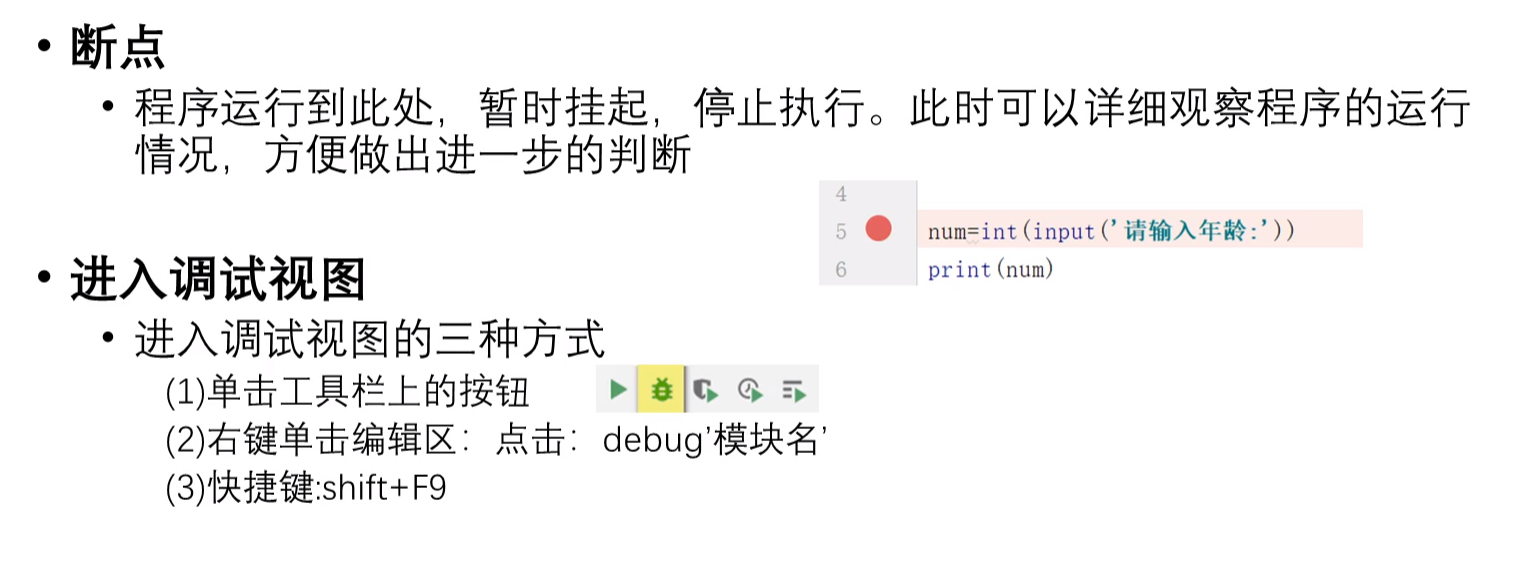
①断点调试
在PyCharm中代码行序号旁边点击一下会出现一个红点,称为设置断点;再次点击红点会消失,称为取消断点。Debug模式下,代码执行到断点处会暂停。
②进入调试视图
12.找对象不积极思想有问题——类与对象
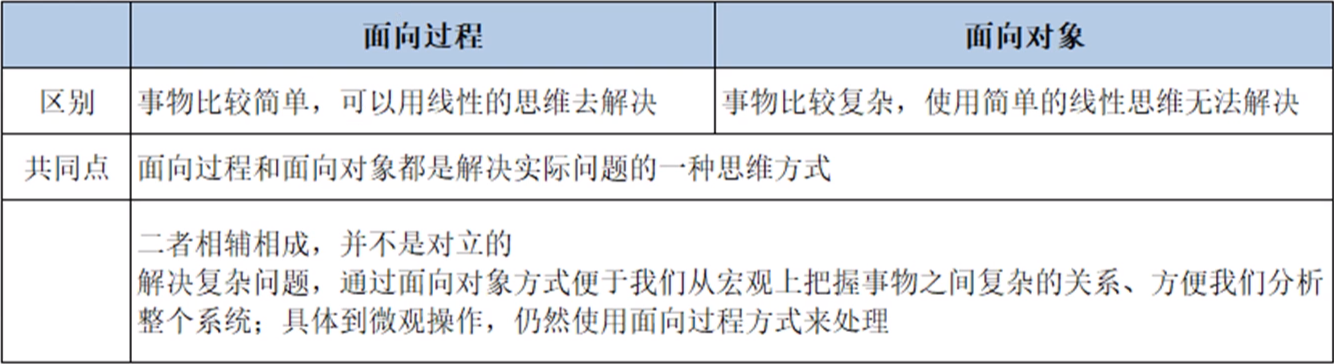
(1)类的概念:类是多个类似事物组成的群体的统称。使用类的概念,可以帮助我们快速理解和判断事物的性质。
(2)数据类型:不同的数据类型属于不同的类,使用内置函数type()可以查看数据的类型。
(3)对象:每个类之下的一个实例就是一个对象,例如1、2、3、4等等同属于int类型下的对象。在Python中,一切皆对象。
(1)创建类的语法
1
2
class 类名:
pass
- 注意事项:类名可以使用一个或多个单词,尽量使用首字母大写、其余字母小写的命名方式遵循规范。
示例:
1
2
3
4
5
class Student:
pass
print(id(Student))
print(type(Student))
print(Student)
结果:
1
2
3
2326387031040
<class 'type'>
<class '__main__.Student'>
(2)类的组成
①类属性:类中方法外的变量称为类属性,被该类的所有对象共享,修改时会影响到该类下所有的对象。
②实例方法:在类内部定义的函数称为实例方法。
③静态方法:使用@staticmethod修饰的方法,使用类名直接访问的方法。
④类方法:使用@classmethod修饰的方法是类方法,使用类名直接访问的方法。
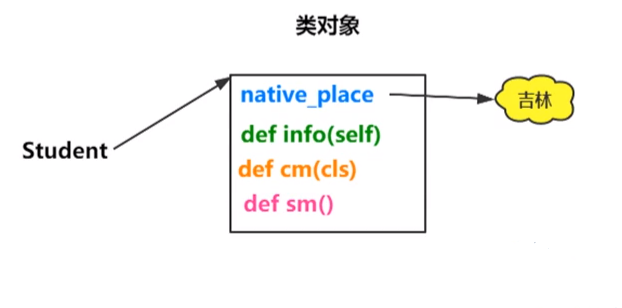
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class Student:
pass
print(id(Student))
print(type(Student))
print(Student)
#类的组成
class Student:
native_place = '浙江' #直接写在类型内的变量,称为类属性
def __init__(self,name,age): #定义初始化方法
self.name = name #self.name称为实例属性,这里进行了赋值,将局部变量name赋值给实例属性self.name,下同
self.age = age
def eat(self): #类之内定义的称为实例方法
print('吃饭')
@staticmethod
def method(): #括号内不能有参数,这是规定
print('使用staticmethod修饰的方法是静态方法')
@classmethod
def cm(cls): #类方法中要求传入一个类作为参数cls
print('使用classmethod修饰的方法是类方法')
def drink(): #类之外定义的称为函数
print('喝水')
(1)创建对象的语法
1
实例名 = 类名()
注意:
①有了实例才可以调用类中的内容。
②实例对象由类指针指向类对象,确定实例对象的类型。
③一个类下可以创建无限个对象,每个对象的属性值可以相同也可以不同。

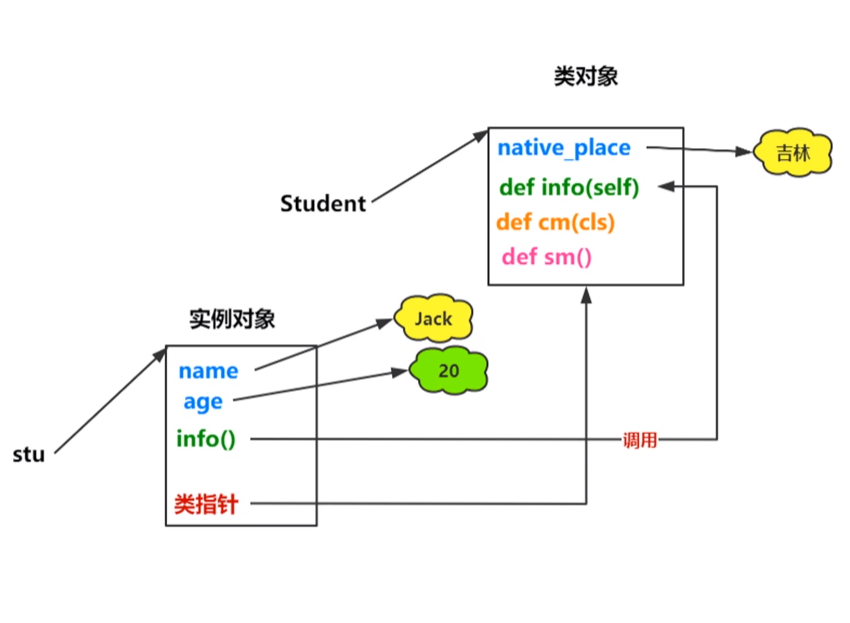
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
class Student:
pass
print(id(Student))
print(type(Student))
print(Student)
#类的组成
class Student:
native_place = '浙江' #直接写在类型内的变量,称为类属性
def __init__(self,name,age): #定义初始化方法
self.name = name #self.name称为实例属性,这里进行了赋值,将局部变量name赋值给实例属性self.name,下同
self.age = age
def eat(self): #类之内定义的称为实例方法
print('吃饭')
@staticmethod
def method(): #括号内不能有参数,这是规定
print('使用staticmethod修饰的方法是静态方法')
@classmethod
def cm(cls): #类方法中要求传入一个类作为参数cls
print('使用classmethod修饰的方法是类方法')
def drink(): #类之外定义的称为函数
print('喝水')
stu1 = Student('张三',20)
#对象的输出
print(id(stu1))
print(type(stu1))
print(stu1)
stu1.eat() #调用方法的方式:对象名.方法名
Student.eat(stu1) #调用方法的方式:类名.方法名(类的对象),这个类的对象就是方法定义处的self,这里传入的是对象,不是参数
print(stu1.name)
print(stu1.age)
#类属性的修改
stu2 = Student('李四',30)
print(stu1.native_place)
print(stu2.native_place)
Student.native_place = '江苏'
print(stu1.native_place)
print(stu2.native_place)
print('-----------类方法的使用-----------')
Student.cm()
print('-----------静态方法的使用-----------')
Student.method()
结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2651227451648
<class '__main__.Student'>
<__main__.Student object at 0x0000026949787100> #这里用十六进制数输出了stu1的ID
吃饭
吃饭
张三
20
浙江
浙江
江苏
江苏
-----------类方法的使用-----------
使用classmethod修饰的方法是类方法
-----------静态方法的使用-----------
使用staticmethod修饰的方法是静态方法
Python是动态语言,在创建对象之后,可以动态地绑定属性和方法。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class Student:
def __init__(self,name,age):
self.name = name
self.age = age
def eat(self):
print(self.name+'吃饭')
stu1 = Student('张三',20)
stu2 = Student('李四',30)
print(id(stu1))
print(id(stu2))
print('----------------------------------')
stu1.gender = '女' #动态绑定对象stu1的gender属性
print(stu1.name,stu1.age,stu1.gender)
print(stu2.name,stu2.age,stu2.gender) #动态绑定只针对stu1,stu2不具备gender属性
stu1.eat()
stu2.eat() #类方法二者都可使用
def show():
print('定义在类之外的为函数')
stu1.show = show() #动态绑定对象stu1的show()方法
stu1.show()
stu2.show() #动态绑定只针对stu1,stu2不具备show()方法
结果:
1
2
3
4
5
6
7
8
2068412867344
2068383232256
----------------------------------
张三 20 女
张三吃饭
李四吃饭
定义在类之外的为函数
TypeError: 'NoneType' object is not callable
13.接着找对象——面向对象的三大特征、object类、特殊方法与特殊属性
(1)封装:提高程序的安全性
①定义:将数据(属性)和行为(方法)包装到类对象中,在方法内部对属性进行操作,在类对象的外部调用方法。
②意义:封装后,调用方法时无需关心方法内部的具体实现细节,从而隔离了复杂度。
③注意:在Python中没有专门的修饰符用于属性的私有化,如果不希望该属性在类对象外部被访问,则在其前边使用两个下划线(_)。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
class Car:
def __init__(self,brand):
self.brand = brand
def start(self):
print('汽车启动')
car = Car('宝马X5')
car.start()
print(car.brand)
class Student:
def __init__(self,name,age):
self.name = name
self.__age = age
def show(self):
print(self.name,self.__age)
stu = Student('张三',20)
stu.show()
print(stu.name)
print(stu.__age)
print(dir(stu))
print(stu._Student__age)
结果:
1
2
3
4
5
6
7
汽车启动
宝马X5
张三 20
张三
AttributeError: 'Student' object has no attribute '__age'
['_Student__age', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'name', 'show']
20
(2)继承:提高代码的复用性
①语法格式:
1
2
class 子类类名(父类1,父类2,……):
pass
②注意:
- 如果一个类没有继承任何类,则默认继承
object。 - Python支持多继承。
- 定义子类时,必须在其构造函数中调用父类的构造函数。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
class Person(object): #Person继承object类
def __init__(self,name,age):
self.name = name
self.age = age
def info(self):
print(self.name,self.age)
class Student(Person):
def __init__(self,name,age,stu_no):
super().__init__(name,age)
self.stu_no = stu_no
class Teacher(Person):
def __init__(self,name,age,teachofyear):
super().__init__(name,age)
self.teachofyear = teachofyear
stu = Student('张三',20)
teacher = Teacher('李四',34,10)
stu.info() #info()方法从父类Person中继承
teacher.info()
#多继承
class A(object): #object类下创建子类A
pass
class B(object): #object类下创建子类B
pass
class C(A,B): #C类同时继承了A与B类,其有两个父类A与B
pass
结果:
1
2
张三 20
李四 34
(3)方法重写:
①如果子类对继承自父类的某个属性或者方法不满意,可以在子类中对其属性(或方法体)进行重写。
②子类重写后的方法中可以通过“super.().xxx()”的格式调用父类中被重写的方法。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class Person(object): #Person继承object类
def __init__(self,name,age):
self.name = name
self.age = age
def info(self):
print(self.name,self.age)
class Student(Person):
def __init__(self,name,age,stu_no):
super().__init__(name,age)
self.stu_no = stu_no
class Teacher(Person):
def __init__(self,name,age,teachofyear):
super().__init__(name,age)
self.teachofyear = teachofyear
stu = Student('张三',20)
teacher = Teacher('李四',34,10)
stu.info() #info()方法从父类Person中继承
teacher.info()
结果:
1
2
张三 20
李四 34
(4)多态:提高程序的可扩展性和可维护性
①定义:简单地说,多态就是“具有多种形态”,指的是即便不知道一个变量所引用的对象到底是什么类型,仍然可以通过这个变量调用方法,在运行过程中根据变量所引用对象的类型,动态决定调用哪个对象中的方法。
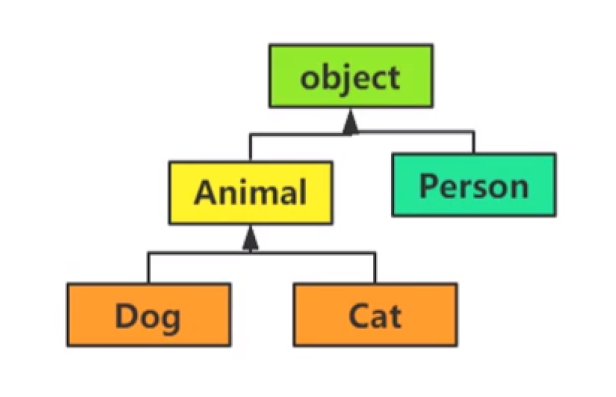
②在Python中,变量不具有数据类型,但是变量具有多态特征。
③在Python中,并不关心对象的类型,在调用方法时只关心其是否具有这个方法。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class Animal(object):
def eat(self):
print('动物要吃东西')
class Dog(Animal):
def eat(self):
print('狗吃肉')
class Cat(Animal):
def eat(self):
print('猫吃鱼')
class Person(object):
def eat(self):
print('人吃五谷杂粮')
def fun(animal):
animal.eat()
fun(Dog())
fun(Cat())
fun(Animal())
fun(Person())
结果:
1
2
3
4
狗吃肉
猫吃鱼
动物要吃东西
人吃五谷杂粮
(1)object类是所有类的父类,因此所有类都有object类的属性和方法。
(2)使用内置函数dir()可以查看指定对象所有属性。
(3)object类有一个__str()__方法,用于返回一个“对于对象的描述”,对应于内置函数str()经常用于print()方法,可以帮助我们查看对象信息,所以我们经常会对__str()__进行重写。
示例1:查看object类的属性
1
2
3
4
5
class Student:
pass
stu = Student()
print(dir(stu))
print(stu)
结果:
1
2
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__'] #object类中的属性
<__main__.Student object at 0x000001DA784C8FD0> #输出对象的内存地址
示例2:重写方法返回对象属性
1
2
3
4
5
6
7
8
9
10
class Student:
def __init__(self,name,age):
self.name = name
self.age = age
def __str__(self):
return('姓名:{0},年龄:{1}'.format(self.name,self.age))
stu = Student('张三',20)
print(dir(stu))
print(stu) #默认会调用__str()__方法
print(type(stu))
结果:
1
2
3
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'age', 'name']
姓名:张三,年龄:20
<class '__main__.Student'>
(1)静态语言(如Java)实现多态的三个必要条件:继承、方法重写、父类引用指向子类对象。
(2)动态语言(如Python)的多态崇尚“鸭子类型”:当看到一只鸟走起来像鸭子,游起来也像鸭子时,那么这只鸟就可以被称为鸭子。在鸭子类型中,不需要关心对象是什么类型、到底是不是鸭子,只关心对象的行为。
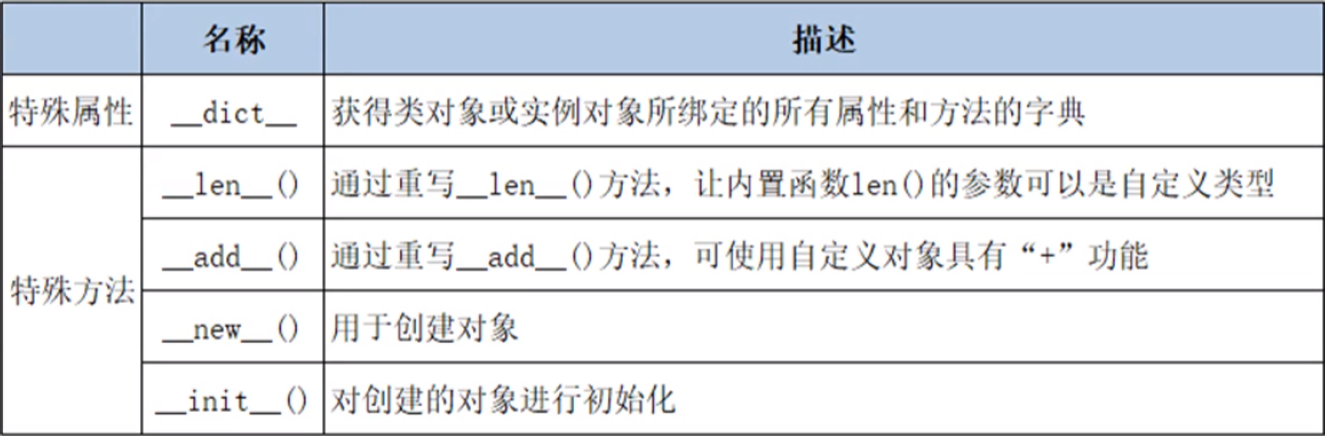
示例1:特殊属性的输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class A:
pass
class B:
pass
class C(A,B):
def __init__(self,name,age):
self.name = name
self.age = age
class D(A):
pass
x = C('Jack',20)
print(x.__dict__) #输出实例对象的属性字典
print(C.__dict__)
print(x.__class__) #输出对象所属的类
print(C.__bases__) #输出C的父类类型的元素
print(C.__base__) #输出继承的第一个父类
print(C.__mro__) #输出类的层级对象
print(A.__subclasses__()) #输出A的子类列表
结果:
1
2
3
4
5
6
7
{'name': 'Jack', 'age': 20}
{'__module__': '__main__', '__init__': <function C.__init__ at 0x000001FC46377F70>, '__doc__': None}
<class '__main__.C'>
(<class '__main__.A'>, <class '__main__.B'>)
<class '__main__.A'>
(<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>)
[<class '__main__.C'>, <class '__main__.D'>]
示例2:特殊方法的定义与使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#类对象的加法:特殊方法__add__()定义
class Student:
def __init__(self,name):
self.name = name
def __add__(self, other):
return self.name+other.name
def __len__(self):
return len(self.name)
stu1 = Student('张三')
stu2 = Student('李四')
s = stu1 + stu2
print(s)
s = stu1.__add__(stu2)
#特殊方法__len__()的定义
list = [1,2,3,4]
print(len(list))
print(list.__len__())
print(len(stu1))
结果:
1
2
3
4
5
6
120
120
张三李四
4
4
2
示例3:特殊方法__new__()创建对象和__init__()初始化对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class Person(object):
def __new__(cls, *args, **kwargs):
print('__new__被调用执行,cls的ID值为{0}'.format(id(cls)))
obj = super().__new__(cls)
print('创建的对象的ID为{0}'.format(obj))
return obj
def __init__(self,name,age):
print('__init__被调用执行,self的ID值为{0}'.format(id(self)))
self.name = name
self.age = age
print('object类对象的ID为{0}'.format(id(object)))
print('Person类对象的ID为{0}'.format(id(Person)))
p1 = Person('张三',20)
print('Person类中的实例对象p1的ID值为{0}'.format(id(p1)))
结果:
1
2
3
4
5
6
object类对象的ID为140733687774032
Person类对象的ID为1817520433184
__new__被调用执行,cls的ID值为1817520433184
创建的对象的ID为<__main__.Person object at 0x000001A72E8C9880>
__init__被调用执行,self的ID值为1817552132224
Person类中的实例对象p1的ID值为1817552132224
(1)变量的赋值操作:多个变量赋值相同(类相同,值相同)时,只是形成多个变量,实际上还是指向同一个对象。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
class CPU:
pass
class Disk:
pass
class Computer:
def __init__(self,cpu,disk):
self.cpu = cpu
self.disk = disk
cpu1 = CPU()
cpu2 = cpu1
print(cpu1)
print(cpu2)
结果:
1
2
<__main__.CPU object at 0x000001EF92969AF0>
<__main__.CPU object at 0x000001EF92969AF0> #上下两行ID相同
(2)浅拷贝:Python拷贝在没有特殊说明时一般都是浅拷贝。浅拷贝时,对象包含的子对象内容不拷贝,因此源对象与拷贝对象会引用同一个子对象,复制后的新对象与源对象为两个ID不同的对象。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class CPU:
pass
class Disk:
pass
class Computer:
def __init__(self,cpu,disk):
self.cpu = cpu
self.disk = disk
cpu1 = CPU()
disk = Disk()
computer = Computer(cpu1,disk)
print(cpu1)
print(disk)
import copy
computer2 = copy.copy(computer)
print(computer,computer.cpu,computer.disk)
print(computer2,computer2.cpu,computer2.disk)
结果:
1
2
3
4
<__main__.CPU object at 0x00000146FF569AF0>
<__main__.Disk object at 0x00000146FF569B20>
<__main__.Computer object at 0x00000146FF569B50> <__main__.CPU object at 0x00000146FF569AF0> <__main__.Disk object at 0x00000146FF569B20>
<__main__.Computer object at 0x00000146FF569C40> <__main__.CPU object at 0x00000146FF569AF0> <__main__.Disk object at 0x00000146FF569B20> #注意上下二者的ID不一致,但是子对象cpu和disk的ID是一致的
(3)深拷贝:使用copy模块的deepcopy函数,递归拷贝对象中包含的子对象,源对象和拷贝对象所有的子对象也不相同,子对象都被拷贝为一个ID不同的新对象。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class CPU:
pass
class Disk:
pass
class Computer:
def __init__(self,cpu,disk):
self.cpu = cpu
self.disk = disk
cpu1 = CPU()
disk = Disk()
computer = Computer(cpu1,disk)
print(cpu1)
print(disk)
import copy
computer3 = copy.deepcopy(computer)
print(computer,computer.cpu,computer.disk)
print(computer3,computer3.cpu,computer3.disk)
结果:
1
2
3
4
<__main__.CPU object at 0x000001EAE2B49AF0>
<__main__.Disk object at 0x000001EAE2B49B20>
<__main__.Computer object at 0x000001EAE2B49B50> <__main__.CPU object at 0x000001EAE2B49AF0> <__main__.Disk object at 0x000001EAE2B49B20>
<__main__.Computer object at 0x000001EAE2B49D00> <__main__.CPU object at 0x000001EAE2B540D0> <__main__.Disk object at 0x000001EAE2B54130> #注意上下二者的ID不一致,但是子对象cpu和disk的ID也不一致
14.百宝箱——模块、包
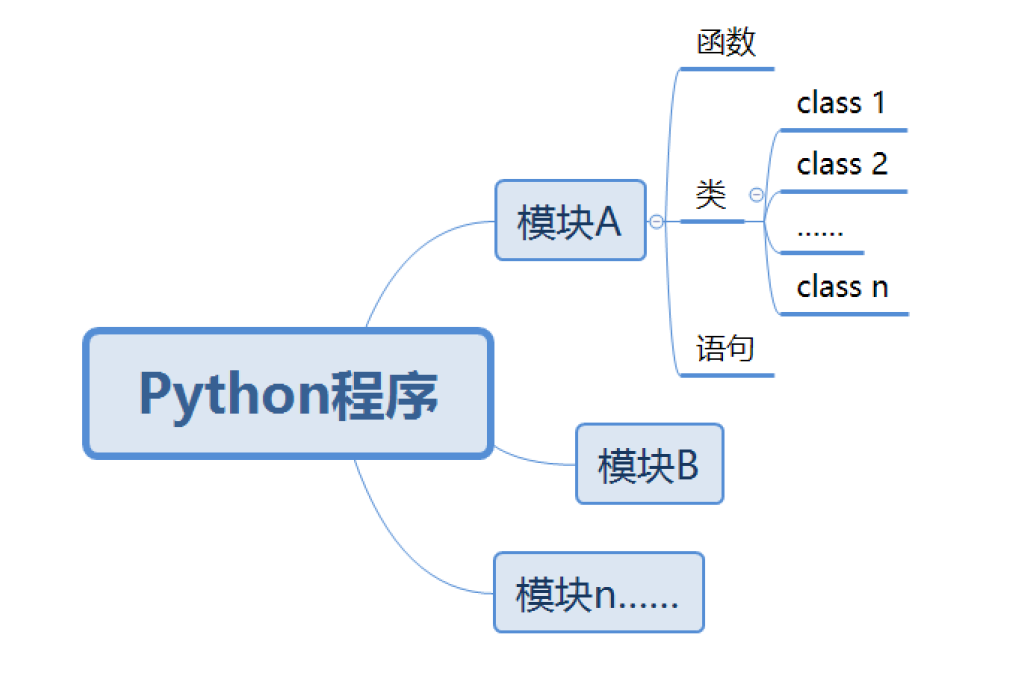
(1)定义:模块(Modules)为函数、类和语句的集合体,一个模块中可以有无限多个函数,在Python中,一个.py文件即为一个模块。
(2)优点:
①方便其他程序及脚本的导入与使用;
②避免函数名和变量名冲突;
③提高代码的可维护性;
④提高代码的可扩展性。
(3)层级图:
(1)创建模块
即新建一个.py文件,名称尽量不要与Python自带的标准模块相同。
(2)导入模块
语法格式:
import 模块名称 [as 别名]
from 模块名称 import 函数/变量/类
①内置模块的导入
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
import math
print(id(math))
print(type(math))
print(math)
print(math.pi)
print(dir(math))
print(pow(2,3))
from math import pi
print(pi)
print(pow(2,3))
print(math.pow(2,3))
from math import pow
print(pow(2,3))
结果:
1
2
3
4
5
6
7
8
9
10
1921037917136
<class 'module'>
<module 'math' (built-in)>
3.141592653589793
['__doc__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'comb', 'copysign', 'cos', 'cosh', 'degrees', 'dist', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose', 'isfinite', 'isinf', 'isnan', 'isqrt', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2', 'modf', 'nan', 'perm', 'pi', 'pow', 'prod', 'radians', 'remainder', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'tau', 'trunc']
8
3.141592653589793
8
8.0
8.0
②自定义模块的导入
自定义模块(.py文件)在导入之前需要在PyCharm左侧窗格中把自定义模块所在的文件夹(Directory)右键---->Make Directory As---->Sources Root进行设置后才可导入其下的.py模块。
示例:
1
2
3
4
5
6
7
8
9
#第一个.py模块文件定义函数:“四则运算.py”
def add(a,b):
return a+b
def sub(a,b):
return a-b
def mul(a,b):
return a*b
def div(a,b):
return a/b
1
2
3
4
5
6
7
8
9
#第二个.py文件调用模块
import 四则运算
a = 10
b = 100
c = 四则运算.add(a,b)
d = 四则运算.sub(a,b)
e = 四则运算.mul(a,b)
f = 四则运算.div(a,b)
print(c,d,e,f)
结果:
1
110 -90 1000 0.1
在每个模块的定义中都包括一个记录模块名称的变量__name__,程序可以检查该变量,以确定它们在哪个模块中执行。如果一个模块不是被导入到其他模块中执行,那么它可能在解释器的顶级模块中执行。顶级模块的__name__变量的值为__main__。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
#第一个.py模块文件定义函数:“四则运算2.py”
def add(a,b):
return a+b
def sub(a,b):
return a-b
def mul(a,b):
return a*b
def div(a,b):
return a/b
if __name__ == '__main__': #只有当“四则运算2.py”为用户点击直接运行的程序(主程序)时才会执行下面的代码
print(add(10,20))
1
2
3
4
5
6
7
8
9
#第二个.py文件调用模块
import 四则运算2
a = 10
b = 100
c = 四则运算2.add(a,b)
d = 四则运算2.sub(a,b)
e = 四则运算2.mul(a,b)
f = 四则运算2.div(a,b)
print(c,d,e,f)
结果:
1
30 #直接执行第一个.py文件
1
110 -90 1000 0.1 #在第二个.py文件中执行
(1)定义:包是一个分层次的目录结构,它将一组功能相近的模块组织在一个目录下。
(2)作用:规范代码、避免模块名称冲突。
(3)包与目录(Directory)的区别:包含__init__.py文件的目录称为包,而目录中一般不包含__init__.py文件。
(4)包的导入:
import 包名.模块名 [as 别名]
(5)示意图:
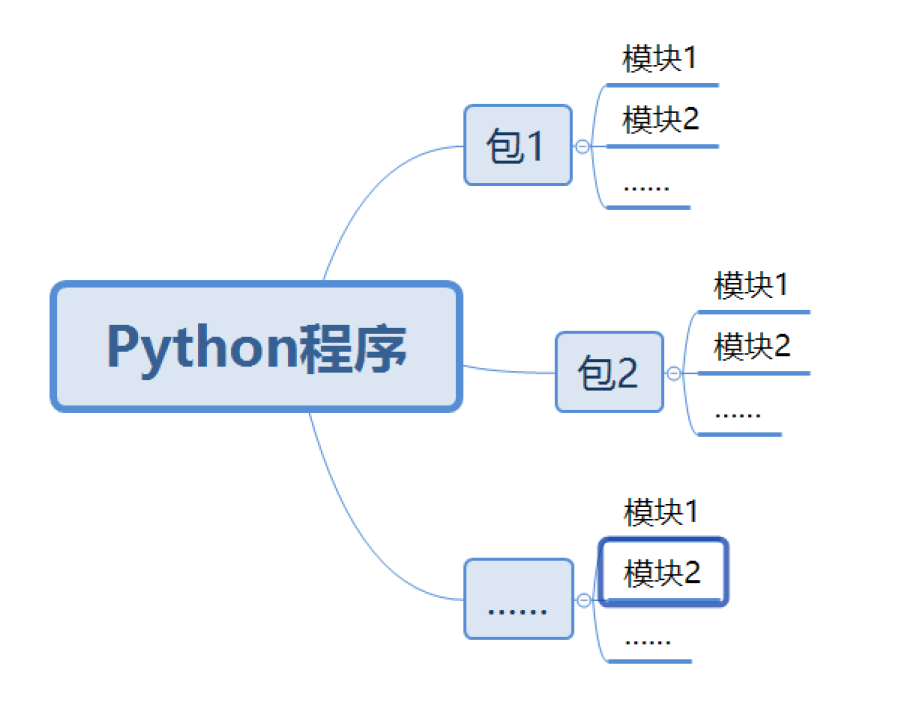
- 注意:不同包中的模块可以重名,但是这些模块的内容未必一致。
(6)在PyCharm中新建包:右键项目下的任意位置,在New子菜单下选择“Python Package”,在其下新建s模块文件。
(7)在导入带有模块的包时的注意事项:
①使用import方式导入时只能跟包名或者模块名。
②使用from…import方式导入时可以导入包、模块、函数变量。
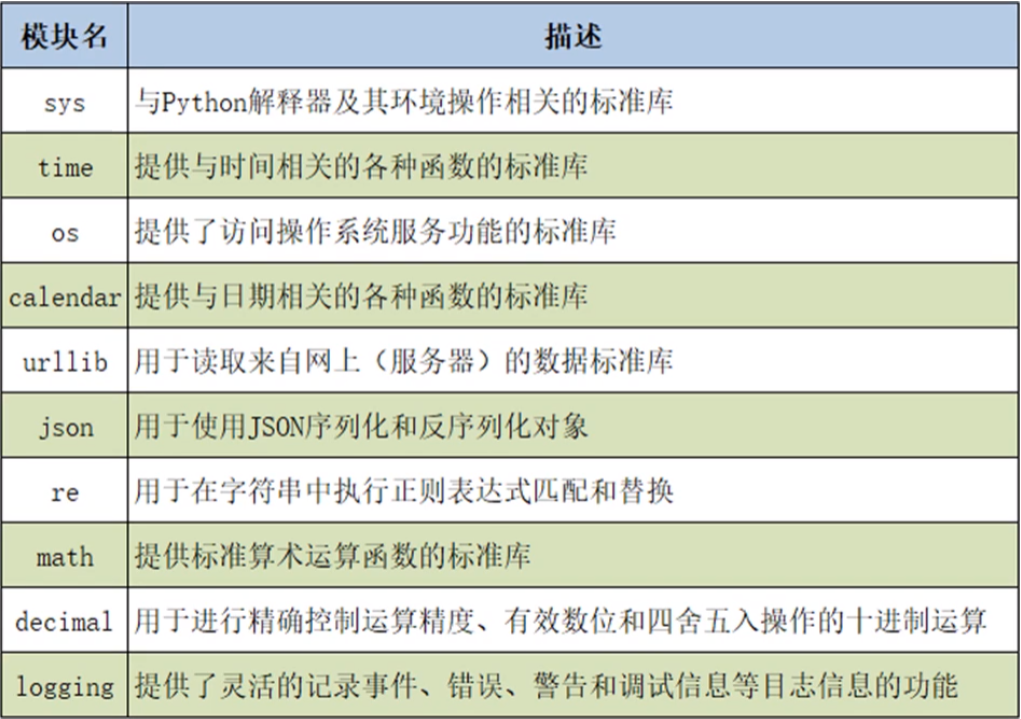
(1)sys:与Python解释器及其环境操作相关的标准库。
示例:
1
2
3
4
5
import sys
print(sys.getsizeof(24)) #getsizeof方法获取对象占用的内存大小,单位:字节
print(sys.getsizeof(45))
print(sys.getsizeof(True))
print(sys.getsizeof(False))
结果:
1
2
3
4
28
28
28
24
(2)time:提供与时间相关的各种函数的标准库。
示例:
1
2
3
4
#time
import time
print(time.time()) #输出结果是秒
print(time.localtime(time.time())) #转换成本地时间
结果:
1
2
1598085163.2238803
time.struct_time(tm_year=2020, tm_mon=8, tm_mday=22, tm_hour=16, tm_min=32, tm_sec=43, tm_wday=5, tm_yday=235, tm_isdst=0)
(3)os:提供了访问操作系统服务功能的标准库。可以用于文件操作。
(4)calendar:提供与日期相关的各种函数的标准库。
(5)urllib:用于读取来自网上(服务器)的数据标准库。
示例:
1
2
import urllib.request
print(urllib.request.urlopen('http://www.baidu.com').read()) #获得百度的网页源代码
结果:
1
百度网页的源代码(过长,不予展示)
(6)json:用于使用JSON序列化和反序列化对象。用于爬虫。
(7)re:用于在字符串中执行正则表达式匹配和替换。用于爬虫。
(8)math:提供标准算术运算函数的标准库。
示例:
1
2
import math
print(math.pi)
结果:
1
3.141592653589793
(9)decimal:用于精确控制运算精度、有效位数和四舍五入操作的十进制运算。
(10)logging:提供了灵活地记录事件、错误、警告和调试信息等日志信息的功能。
(1)安装:
①在线安装(使用的最常用的安装方式):
在PyCharm下方的“Terminal”终端命令行或者Python交互式命令行中键入:
1
pip install 模块名
(2)使用:
语法格式:
1
import 模块名
15.大宝藏——文件操作、目录操作
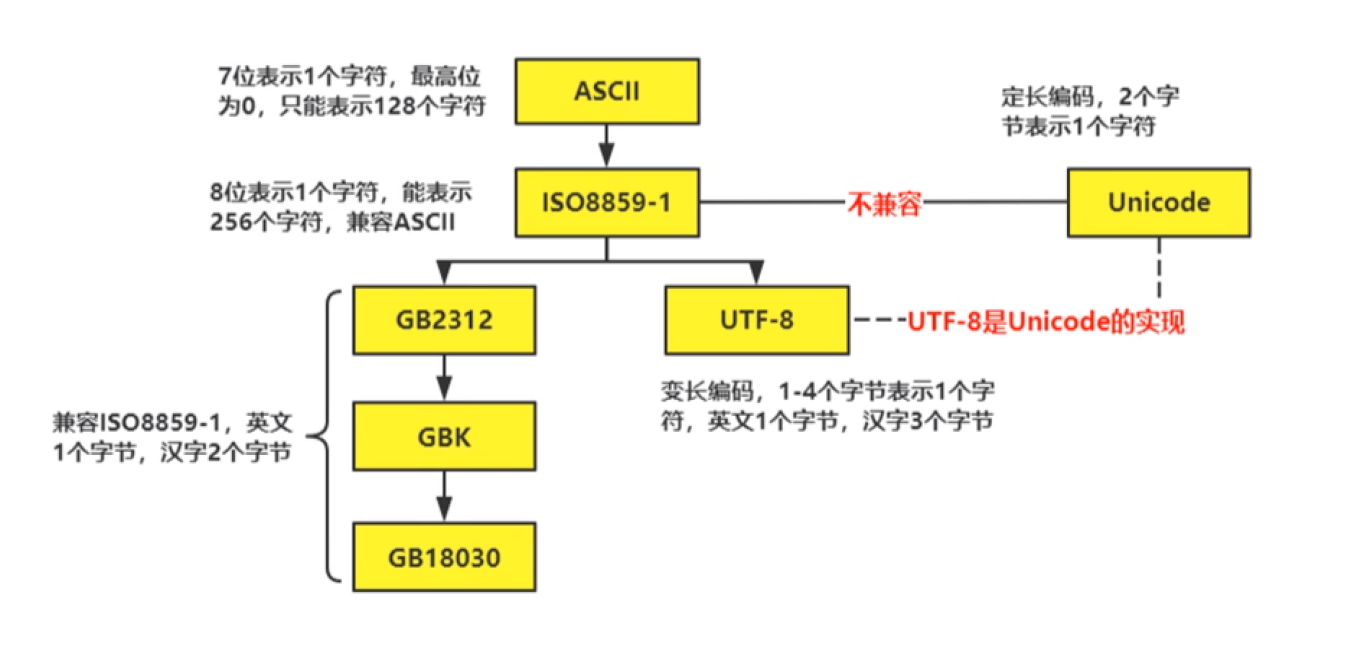
(1)常见的字符编码格式
Python的解释器使用的是Unicode编码格式(内存中)。.py文件在磁盘上默认使用UTF-8编码格式存储(外存中),如果要修改,就需要在.py文件头部加上中文编码声明注释。不同编码格式下相同的内容占用的磁盘空间大小可以不一样。
常见编码格式以及其关系如下图所示:
(2)文件的读写原理
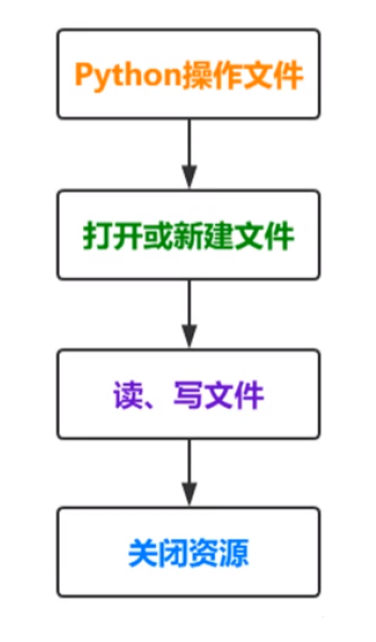
①定义:文件的读写俗称“IO(Input/Output)操作”,是基本的输入输出方式。
②文件读写操作流程
这里运用到了队列的数据结构,先进先出。
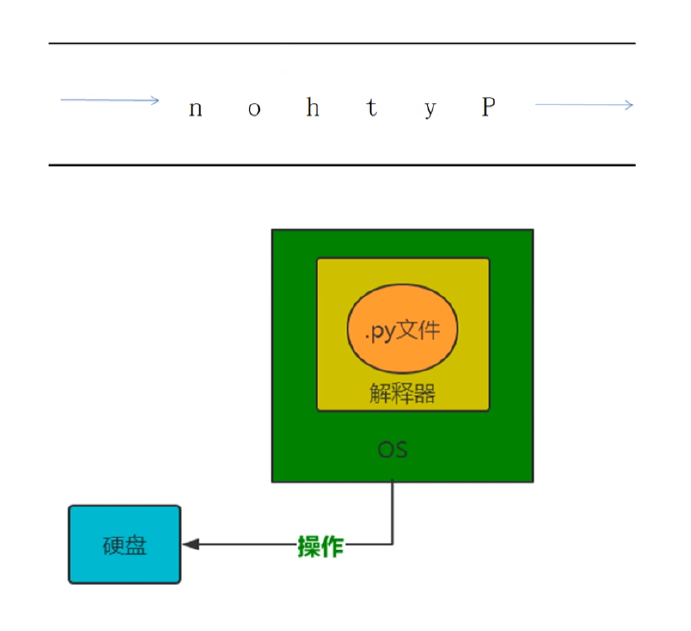
③文件读写操作原理
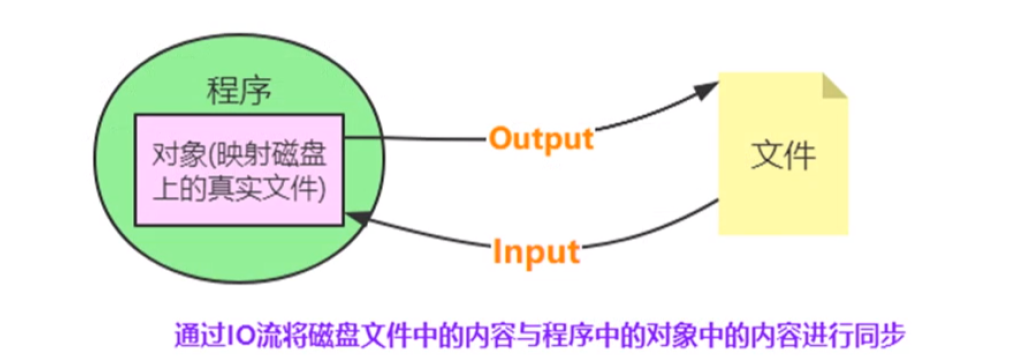
(3)文件的读写操作:
①使用内置函数open()创建文件对象
语法格式:
1
文件 = open(文件名[,模式,编码格式]) #默认文本文件中字符的编码格式为GBK
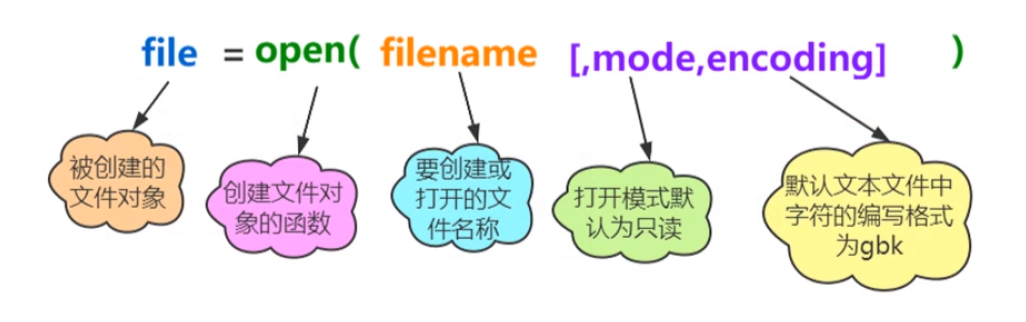
示例(磁盘上同目录下已经有内容为“中国”、“美丽”两行的a.txt,需要文本保存编码为ANSI,并在PyCharm中选择“Reload in GBK”,否则报错):
1
2
3
file = open('a.txt','r') #“r”代表读取
print(file.readlines())
file.close()
结果:
1
['中国\n', '美丽'] #注意结果为列表
②文件的写操作
示例(磁盘上同目录下没有b.txt):
1
2
3
file = open('b.txt','w') #“w”代表写入
file.write('Python')
file.close()
结果:
1
在同目录下生成一个内容为“Python”的文本文件b.txt
(1)文件的类型
按文件中数据的组织形式,文件分为以下两大类:
①文本文件:存储的是普通的”字符“文本,默认为Unicode字符集,可以使用记事本程序打开。
②二进制文件:把数据内容用“字节”进行存储,无法用记事本打开,必须使用专用的软件打开,例如:.mp3音频、.jpg图片、.doc文档。
(2)文件的打开模式
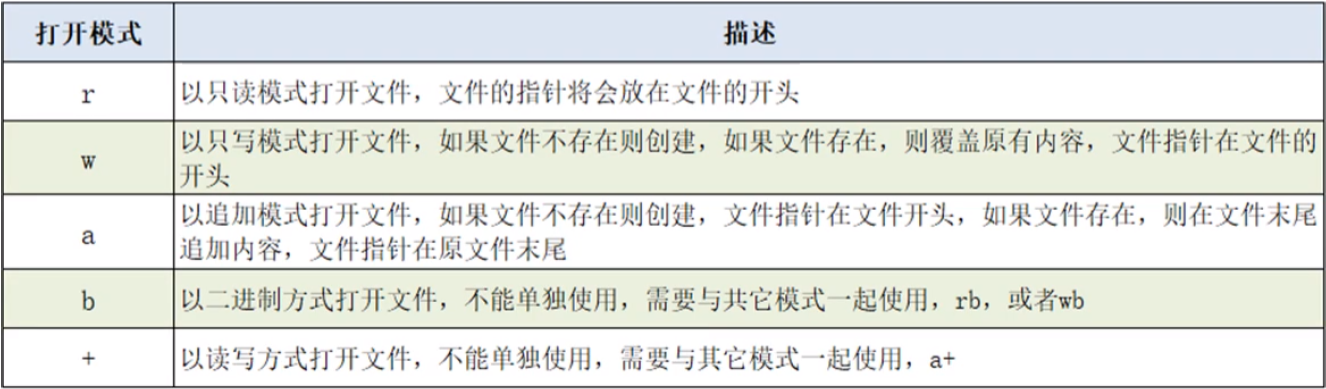
①r:以只读模式打开文件,文件的指针将会放在文件的开头。
②w:以只写模式打开文件,如果文件不存在则创建,如果文件存在,则覆盖原有内容,文件指针在文件的开头。
③a:以追加模式打开文件,如果文件不存在则创建,文件指针在文件开头,如果文件存在,则在文件末尾追加内容,文件指针在原文件末尾。
④b:以二进制方式打开文件,不能单独使用,需要与其他模式一起使用,例如:rb,wb,可以把非文本文件用处理文本文件的方式处理。
⑤+:以读写方式打开文件,不能单独使用,需要与其他模式一起使用,例如:a+。
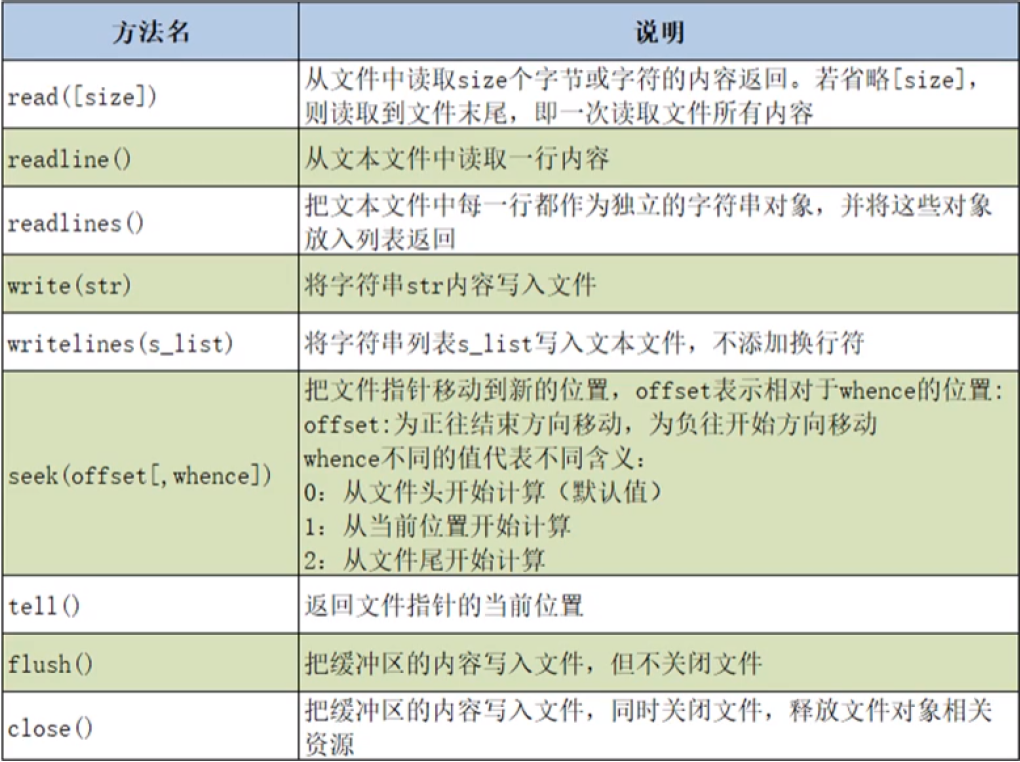
①read([size]):从文件中读取size个字节或字符的内容返回。若省略size,则读取到文件末尾,即一次性读取文件所有内容。
②readline():从文本文件中读取一行内容。
③readlines():把文本文件中每一行都作为独立的字符串对象,并将这些对象放入列表返回。
④write('str'):将字符串str内容写入文件。
⑤writelines([str_list]):将列表str_list的内容写入文本文件,不添加换行符。
⑥seek(offset[,whence]):把文件指针移动到新的位置。offset表示相对于whence的位置,offset为正往文件末尾移动,为负则往文件开头移动。whence不同的值代表不同含义:0:从文件头开始计算(默认值);1:从当前位置开始计算;2:从文件尾开始计算。
⑦tell():返回文件指针的当前位置。
⑧flush():把缓冲区的内容写入文件,但不关闭文件。
⑨close():把缓冲区的内容写入文件,同时关闭文件,释放文件对象相关资源。
(1)作用:with语句可以自动管理上下文资源,不论什么原因跳出with块,都能确保文件正确地关闭,以此来达到释放资源的目的。
(2)with语句的使用
示例(磁盘上同目录下已经有内容为“中国”、“美丽”两行的a.txt,需要文本保存编码为ANSI,并在PyCharm中选择“Reload in GBK”,否则报错):
1
2
with open('a.txt','r') as file:
print(file.read()) #不需要再手动写close()语句,因为文件已经正确关闭
结果:
1
2
中国
美丽
(3)with语句的原理
①上下文表达式:with后,as前的部分。得到的结果是上下文管理器(上下文管理器类的有特殊方法的的一个实例对象)。
②使用with语句无论什么原因退出了with块,文件都会被正确地关闭。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class MyContentManager(object):
def __enter__(self):
print('enter方法执行')
def __exit__(self, exc_type, exc_val, exc_tb):
print('exit方法执行')
def show(self):
print('show方法执行')
print(type(open('a.txt','r')))
with MyContentManager() as file:
MyContentManager.show(file)
结果:
1
2
3
4
<class '_io.TextIOWrapper'>
enter方法执行
show方法执行
exit方法执行
③原理示意图
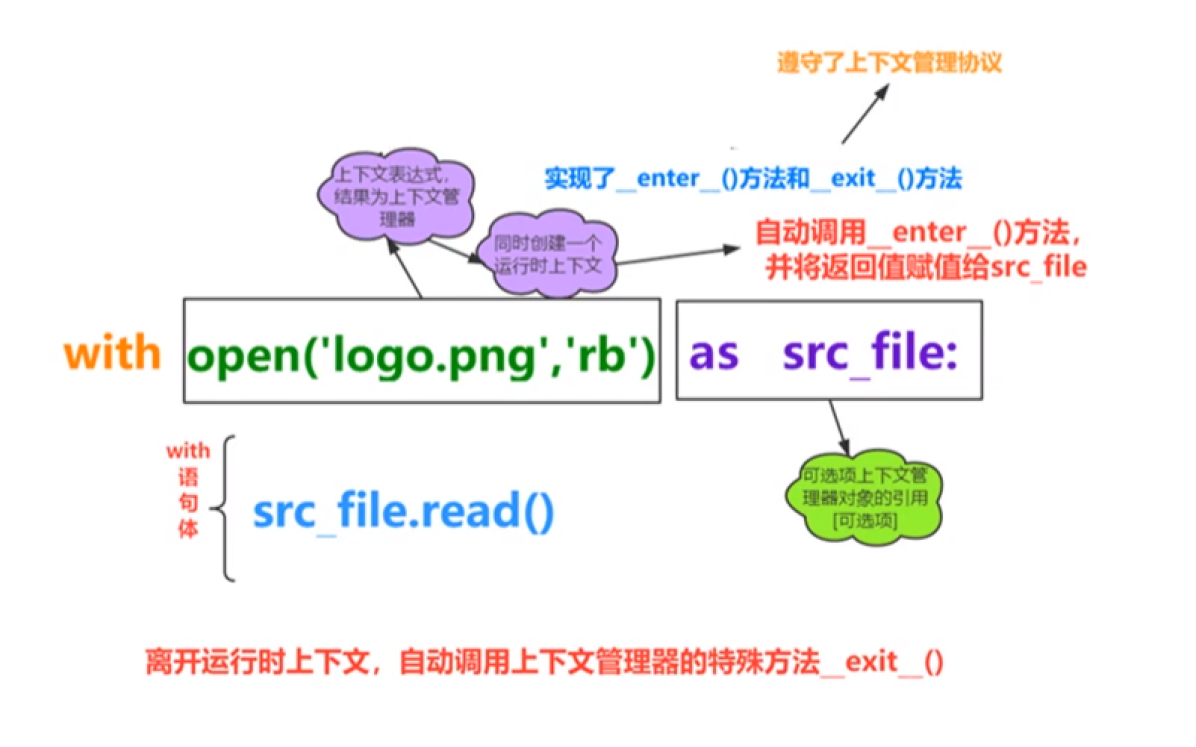
(1)os模块是Python内置的与操作系统功能和文件系统相关的模块,该模块中的语句的执行结果通常与操作系统有关,在不同的操作系统上运行,得到的结果可能不一样。
(2)os模块与os.path模块用于对目录或文件进行操作。
(3)os模块中的目录操作相关函数
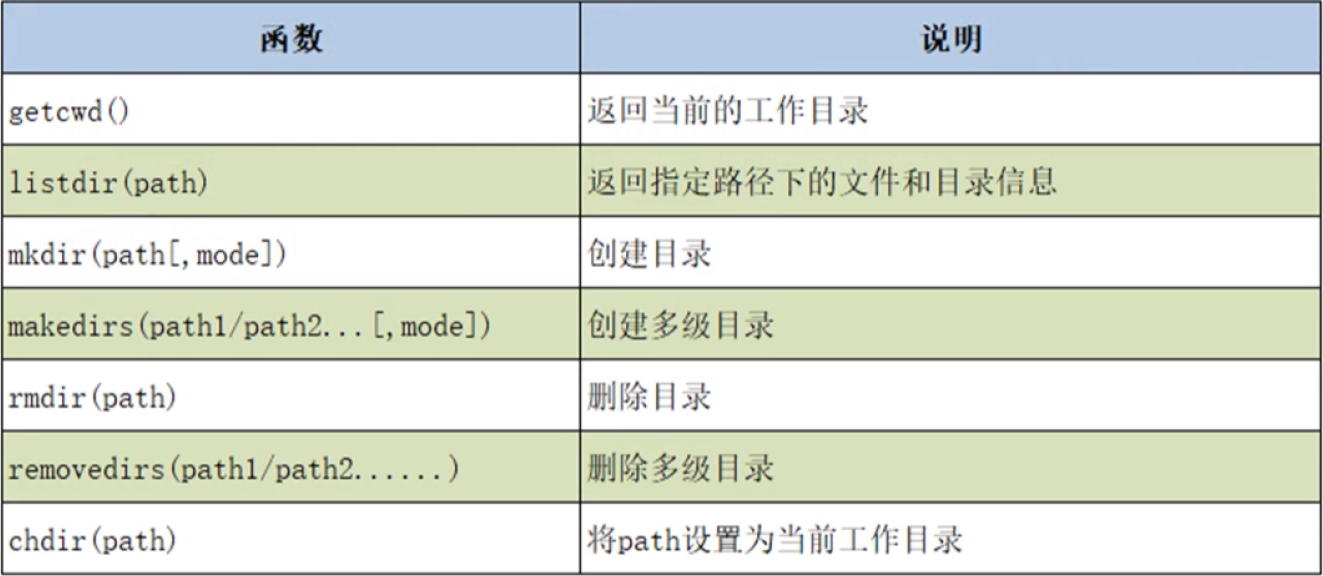
①getcwd():返回当前的工作目录,一般与print()函数一起使用。
示例:
1
print(os.getcwd())
②listdir():返回指定路径下的文件和目录信息,一般与print()函数一起使用。
示例:
1
print(os.listdir('../Python基础语法')) #注意引号
③mkdir():创建单级目录。
示例:
1
os.mkdir('目录名')
④makedirs():创建多级目录。
示例:
1
os.makedirs('一级目录/二级目录/三级目录')
⑤rmdir():删除指定目录。
⑥removedirs():删除多级目录。
示例:
1
os.removedirs('一级目录/二级目录/三级目录')
⑦chdir():改变当前工作目录至指定目录下。
⑧walk():遍历指定目录以及其下所有的文件与子目录中的文件,并按照路径、目录名、文件名的顺序存储。
(4)os.path模块中的目录操作相关函数
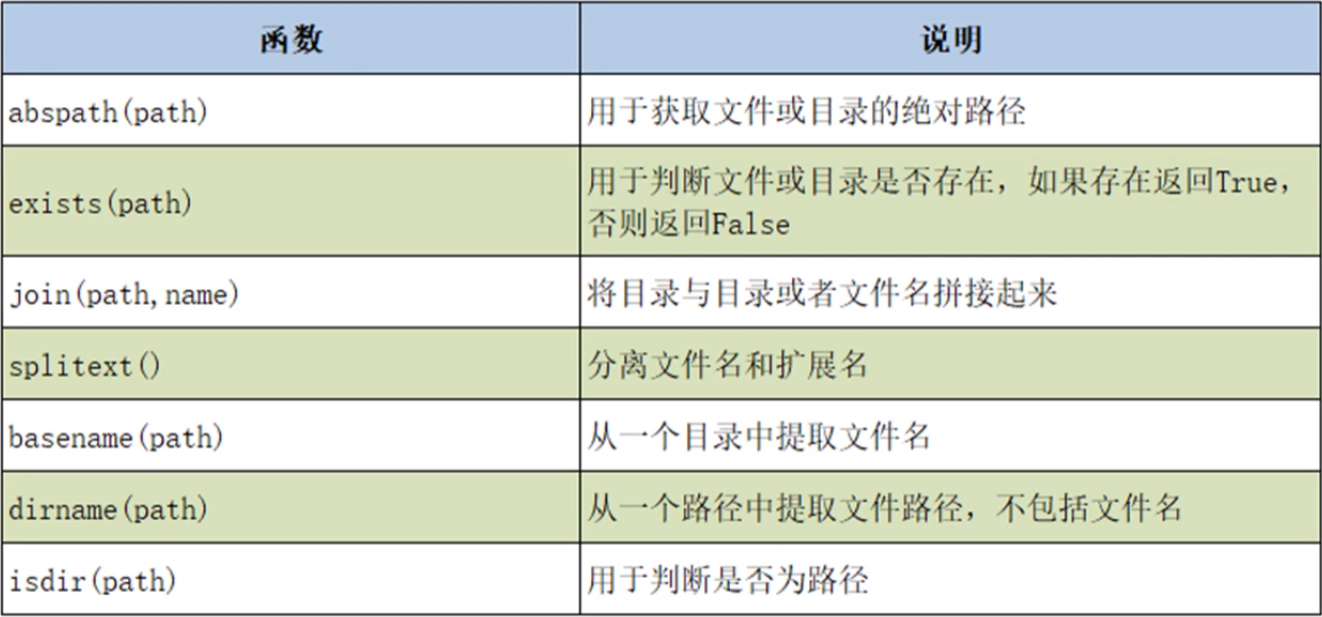
①abspath():用于获取文件或目录的绝对路径,默认获取当前工作目录下的文件或者目录的绝对路径。即使文件不存在,也会返回“当前工作目录绝对路径\文件名”格式的结果。
示例:
1
os.path.abspath('文件名或目录名')
②exists():用于判断文件或目录是否存在,返回值为布尔值。
③join():将目录与目录或者文件名拼接。
示例:
1
os.path.join('文件绝对路径','文件名')
④splitext():分离文件名和扩展名,返回结果为元组。
示例:
1
os.path.splitext('文件名.扩展名')
⑤basename():从一个路径中提取文件名。
示例:
1
os.path.basename('文件绝对路径\\文件名')
⑥dirname():从一个路径中提取不包含文件名的文件路径。
示例:
1
os.path.dirname('文件绝对路径\\文件名')
⑦isdir():用于判断是否为路径,返回值为布尔值。
- 注意事项:以上目录操作在执行时,所有的路径以及文件名都需要加上引号,并且路径中的反斜杠都必须写两个以防止因为转义导致目录指向错误。
16.大显身手——学生信息管理系统的设计与构建
(1)基本需求:对学生信息进行添加、删除、修改、查询以及排序。
(2)具体要求:
①添加学生及成绩信息;
②将学生信息保存到文件中;
③修改和删除学生信息;
④查询学生信息;
⑤根据学生成绩进行排序;
⑥统计学生的总分。
(1)学生信息管理系统的7大模块
①学生信息录入模块
②学生信息查找模块
③学生信息删除模块
④学生信息修改模块
⑤学生成绩排名模块
⑥统计学生总人数模块
⑦显示全部学生信息模块
(2)学生信息管理系统结构模式图
(3)系统业务流程图
(1)软件要求:
①操作系统:Windows 10
②Python解释器:Python 3.8
③开发工具:PyCharm
④Python内置模块:os,re
(2)项目目录结构

(1)系统主界面
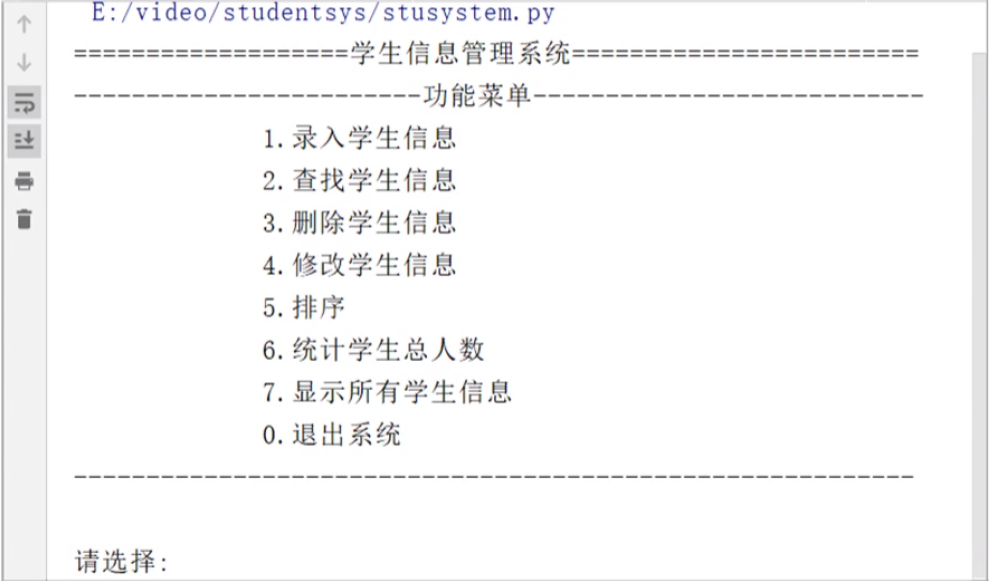
(2)主函数的业务流程图
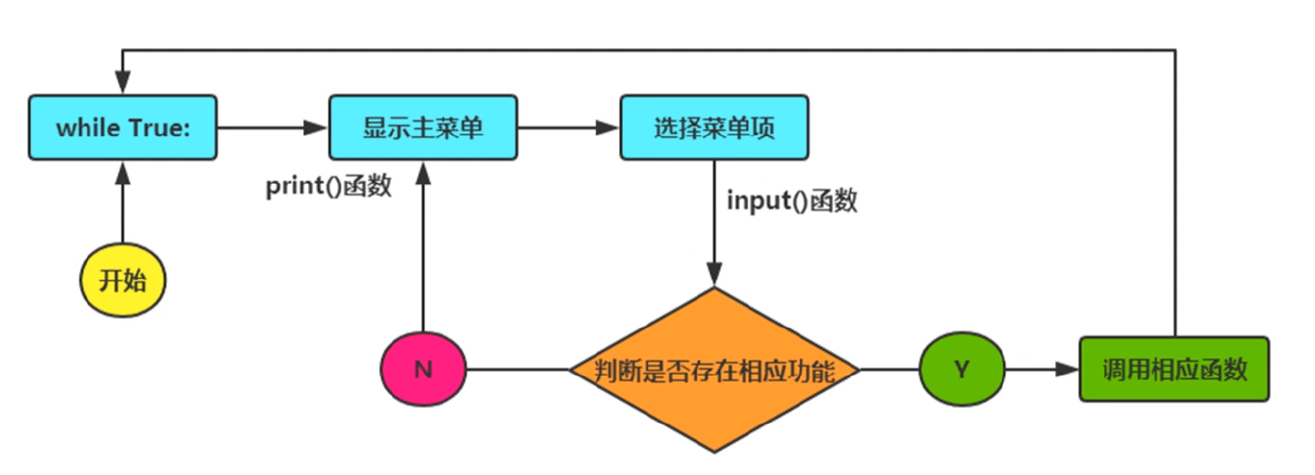
(3)实现主函数
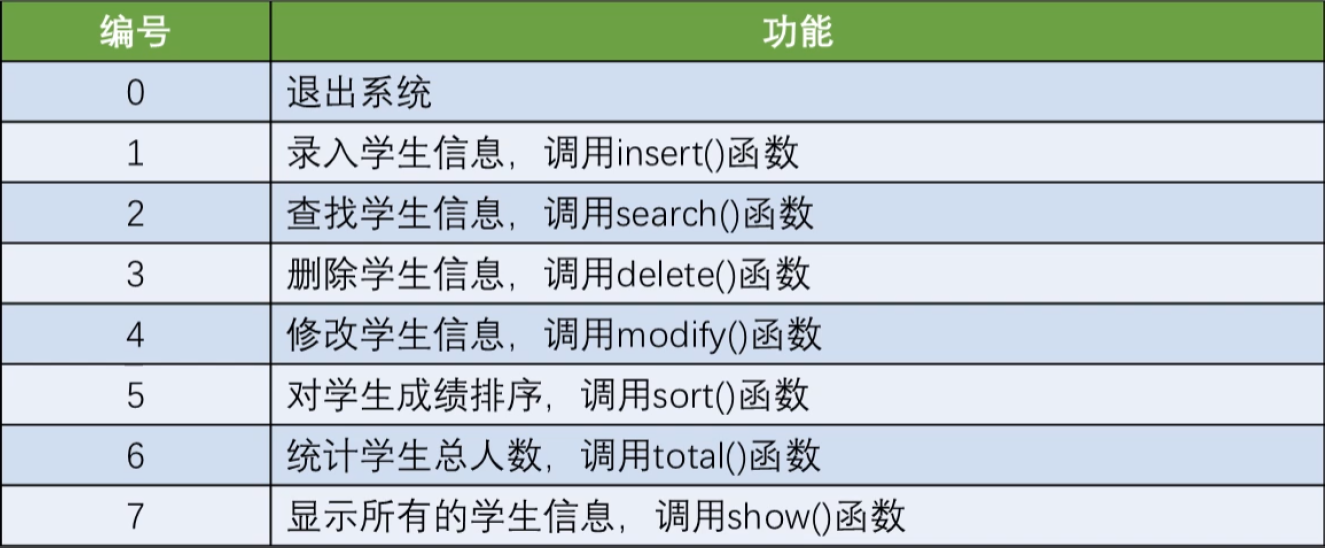
(4)主函数源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
def main():
while True:
try:
menu()
choice = int(input('请选择所需功能的序号:'))
if choice in [0,1,2,3,4,5,6,7]:
if choice == 0:
answer = input('您确定要退出系统吗?(y/n):')
if answer == 'y' or answer == 'Y':
print('感谢使用')
break
else:
continue
elif choice == 1:
insert()
elif choice == 2:
search()
elif choice == 3:
delete()
elif choice == 4:
modify()
elif choice == 5:
sort()
elif choice == 6:
total()
elif choice == 7:
show()
else:
print('输入无效,请重新输入!')
except:
print('输入无效,请重新输入!')
continue
(5)主菜单源码
1
2
3
4
5
6
7
8
9
10
11
12
def menu():
print('=========================学生信息管理系统=========================')
print('-------------------------主菜单---------------------------------')
print('\t\t\t\t\t\t1.录入学生信息')
print('\t\t\t\t\t\t2.查找学生信息')
print('\t\t\t\t\t\t3.删除学生信息')
print('\t\t\t\t\t\t4.修改学生信息')
print('\t\t\t\t\t\t5.学生信息排序')
print('\t\t\t\t\t\t6.统计学生总人数')
print('\t\t\t\t\t\t7.显示所有学生信息')
print('\t\t\t\t\t\t0.退出')
print('==============================================================')
(1)预期实现效果:从控制台录入学生信息并且把它们保存到磁盘文件中。
(2)运行效果图
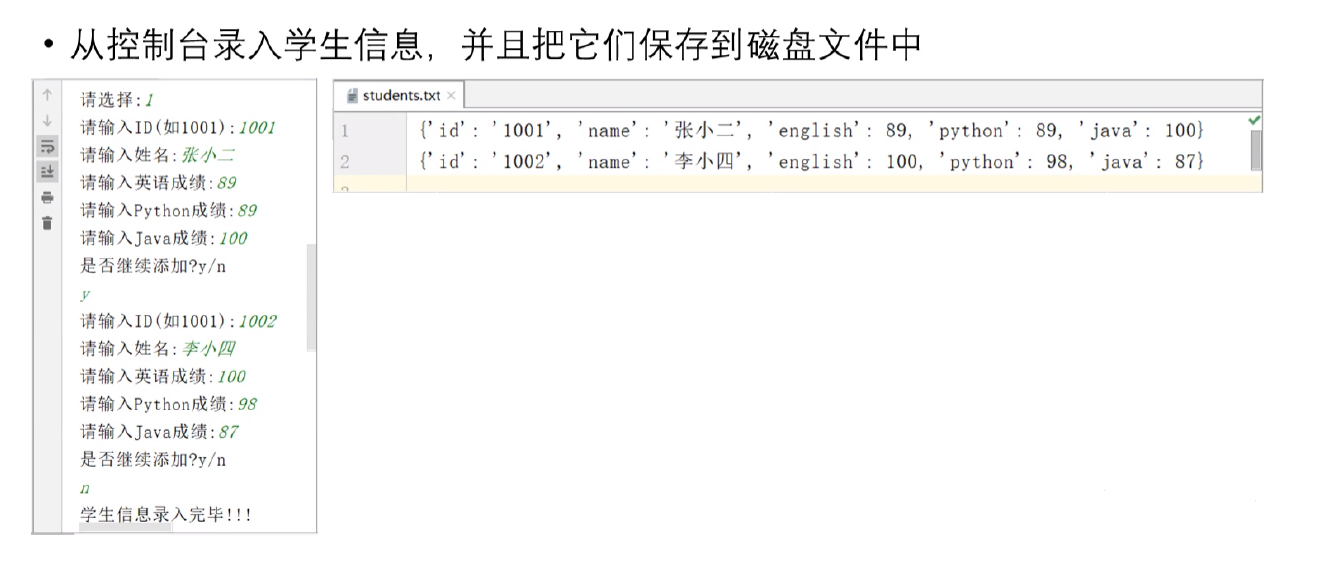
(3)业务流程图
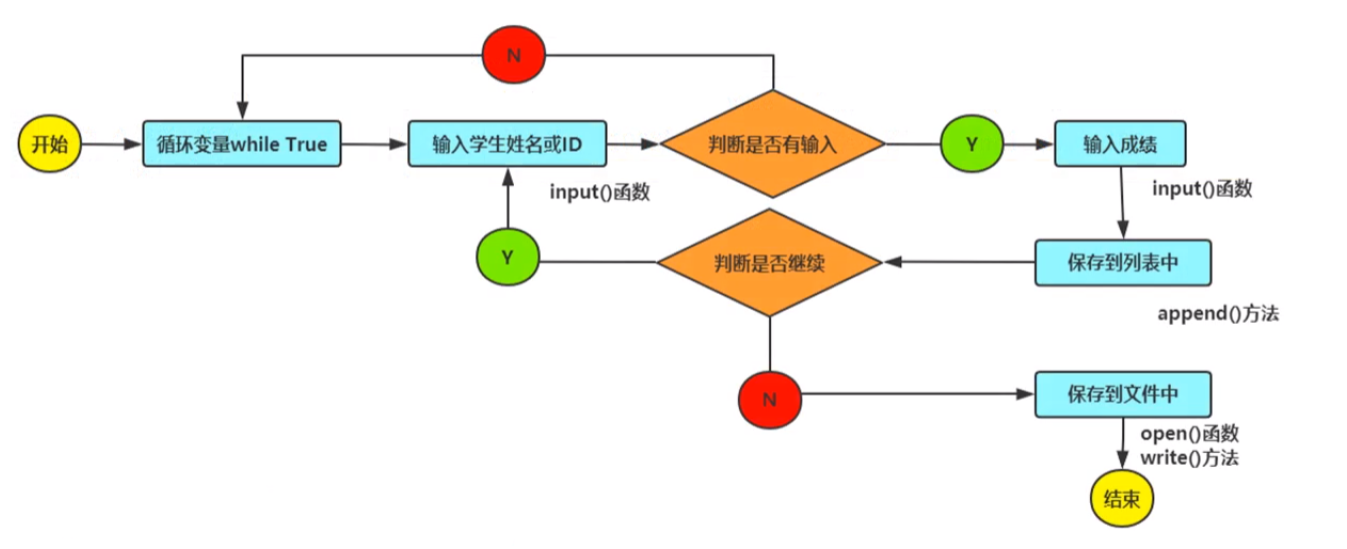
(4)insert()函数与save()函数源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
def insert():
while True:
student_list = []
ID = input('请输入学生ID(如1001):')
if not ID: # 与if ID != '' 功能相同,用于排除输入空字段的情况,直接退出
break
name = input('请输入姓名:')
if not name: # 与if name != ''功能相同,用于排除输入空字段的情况,直接退出
break
try:
english = int(input('请输入英语成绩:'))
python = int(input('请输入Python成绩:'))
java = int(input('请输入Java成绩:'))
except:
print('输入无效,请重新输入!')
continue
student = {'ID': ID, 'name': name, 'english': english, 'python': python, 'java': java} # 将控制台录入的学生信息保存到字典中
student_list.append(student)
save(student_list)
print('学生信息录入完成!')
answer = input('是否继续录入学生信息?(y/n):')
if answer == 'y' or answer == 'Y':
continue
else:
break
(1)预期实现效果:从控制台输入学生ID,然后在磁盘文件中找到对应的学生信息并将其删除。
(2)运行效果图
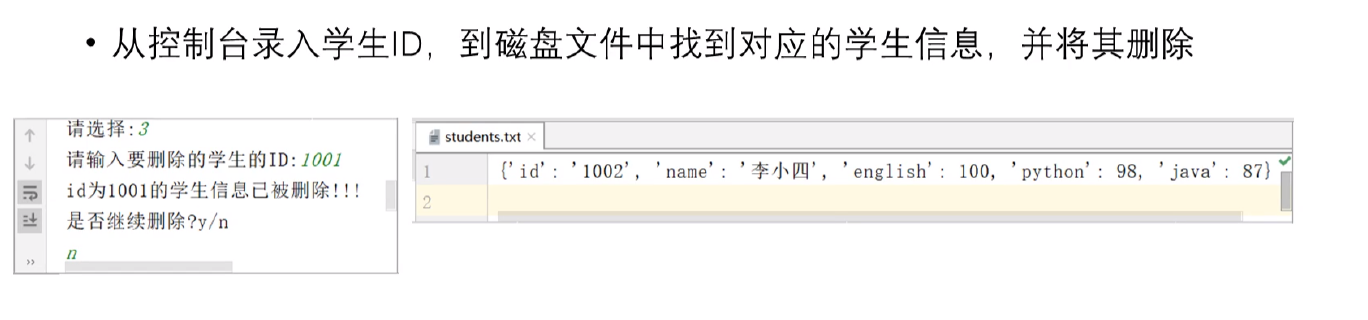
(3)业务流程图
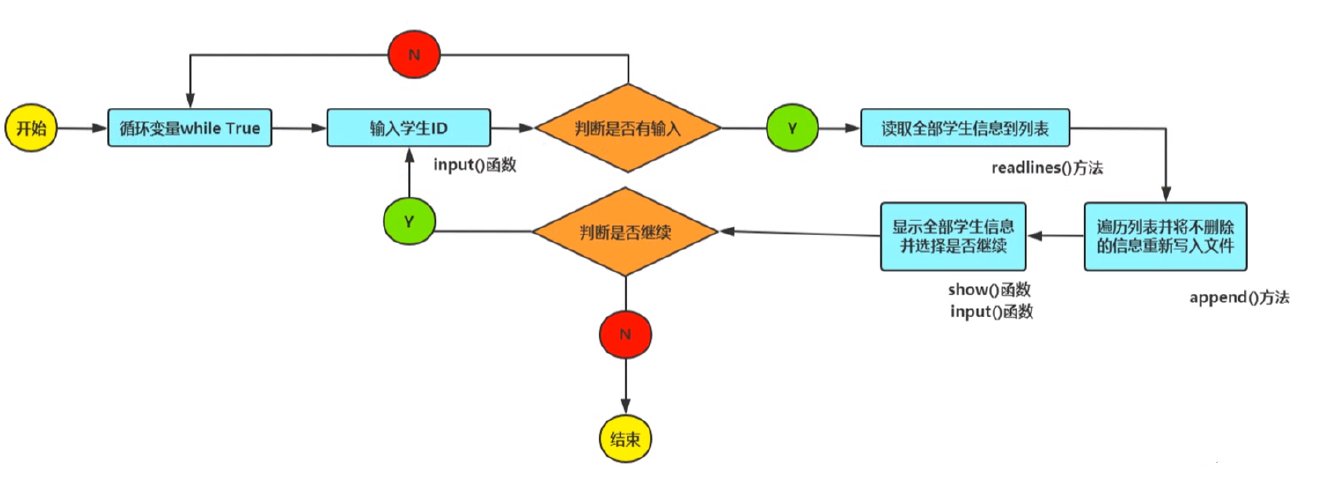
(4)delete()函数源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
def delete():
print('当前所有学生信息:\n')
show()
while True:
student_id = input('请输入需要删除的学生ID:')
if student_id != '':
if os.path.exists(filename):
with open(filename,'r',encoding='utf-8') as file:
student_old = file.readlines()
else:
student_old = []
flag = False
if student_old:
with open(filename,'w',encoding='utf-8') as wfile:
dict = {}
for item in student_old:
dict = dict(eval(item)) #将字符串转换为字典
if dict['id'] != student_id:
wfile.write(str(dict)+'\n') #将一条学生信息写入文件
else:
flag = True #标记已删除
if flag:
print(f'ID为{student_id}的学生信息已删除')
else:
print(f'ID为{student_id}的学生信息未找到')
else:
print('无学生信息')
break
show()
answer = input('是否继续删除学生信息?(y/n):')
if answer == 'y' or answer == 'Y':
continue
else:
break
(1)预期实现效果:从控制台输入学生ID,到磁盘文件中找到对应的学生信息,将其进行修改。
(2)运行效果图
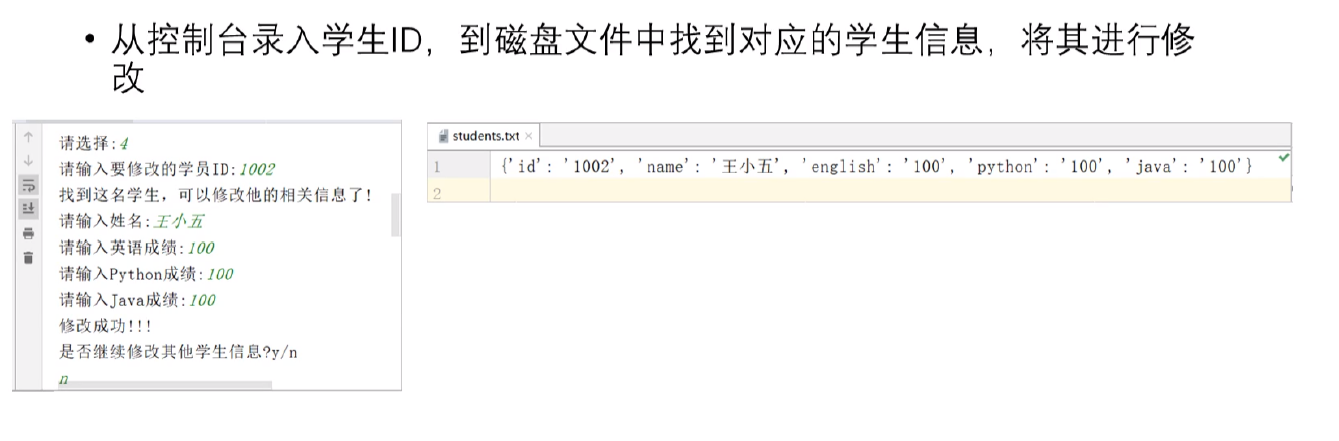
(3)业务流程图
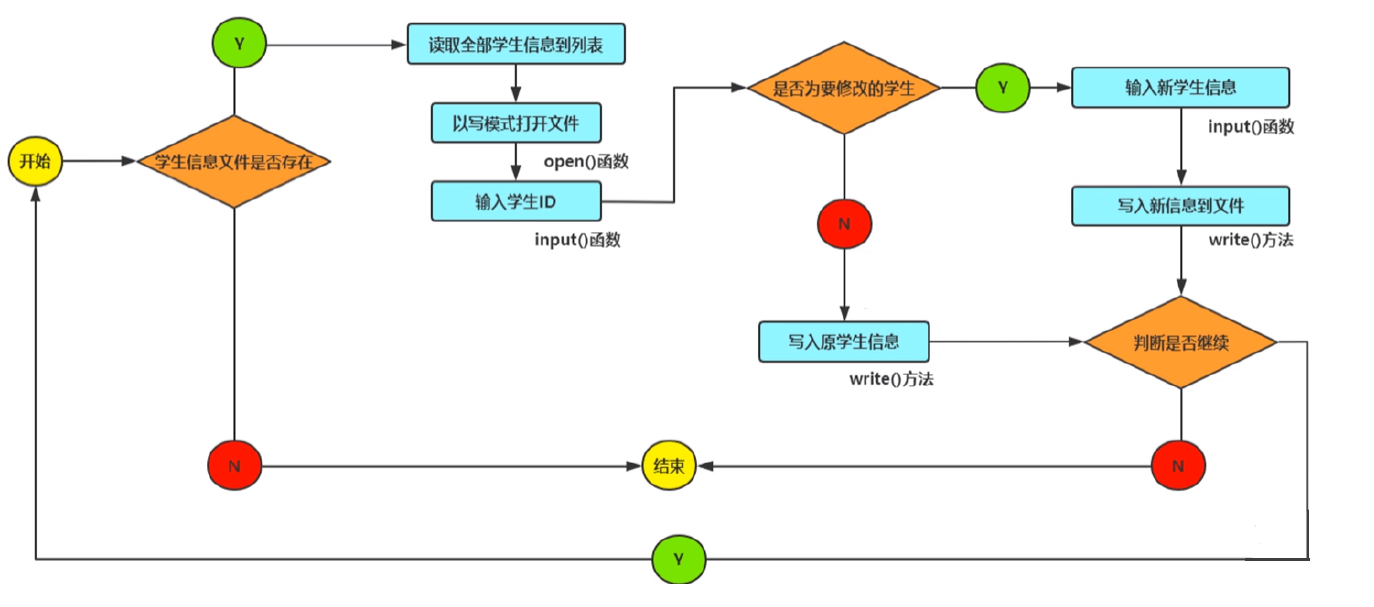
(4)modify()函数源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
def modify():
id_list = []
print('当前所有学生信息:\n')
show()
if os.path.exists(filename):
with open(filename, 'r', encoding='utf-8') as rfile:
student_old = rfile.readlines()
else:
return 0
if student_old == []:
print('当前没有学生信息!')
return 0
student_id = input('请输入需要修改信息的学生ID:')
with open(filename, 'w', encoding='utf-8') as wfile:
for item in student_old: #一次提取一条信息进行比对
d = dict(eval(item))
id_list.append(d['ID'])
if d['ID'] == student_id: #比对ID
print('已找到该学生信息,可以进行修改')
while True:
try:
d['name'] = input('请输入姓名:')
d['english'] = input('请输入英语成绩:')
d['python'] = input('请输入Python成绩:')
d['java'] = input('请输入Java成绩:')
except:
print('输入有误,请重新输入')
else:
break
if d != {}:
wfile.write(str(d) + '\n')
print('学生信息已更新')
else:
wfile.write(str(d) + '\n') # 将未修改的其他学生信息写入文件
if student_id not in id_list:
print('ID输入有误,请查证后重试')
break
answer = input('是否继续进行学生信息修改?(y/n):')
if answer == 'y' or answer == 'Y':
modify()
(1)预期实现效果:从控制台输入学生ID或姓名,到磁盘文件中找到对应的学生信息。
(2)运行效果图

(3)业务流程图
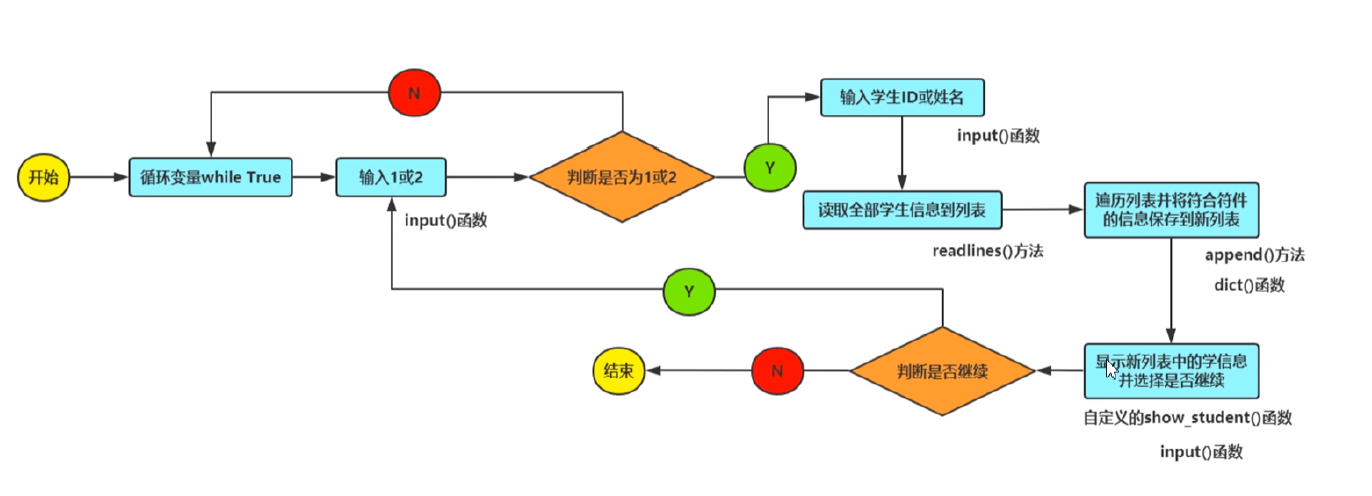
(4)search()函数与show_student()模块源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
def search():
student_query = []
while True:
ID = ''
name = ''
if os.path.exists(filename):
mode = input('请选择查找模式(1.按ID查找 2.按姓名查找):')
if mode == '1':
ID = input('请输入学生ID:')
elif mode == '2':
name = input('请输入学生姓名:')
else:
print('输入有误,请重新输入!')
search()
with open(filename,'r',encoding='utf-8') as rfile:
student = rfile.readlines()
for item in student:
d = dict(eval(item))
if ID != '':
if d['ID'] == ID:
student_query.append(d)
elif name != '':
if d['name'] == name:
student_query.append(d)
show_student(student_query)
student_query.clear()
answer = input('是否继续查询?(y/n):')
if answer == 'y' or answer == 'Y':
continue
else:
break
else:
print('暂未保存学生信息')
return 0
def show_student(list):
if len(list) == 0:
print('未查询到相关学生信息')
return 0
format_title = '{:^6}\t{:^12}\t{:^8}\t{:^10}\t{:^10}\t{:^8}'
print(format_title.format('ID','姓名','英语成绩','Python成绩','Java成绩','总成绩'))
format_data = '{:^6}\t{:^12}\t{:^8}\t{:^10}\t{:^10}\t{:^8}'
for item in list:
print(format_data.format(item.get('ID'),
item.get('name'),
item.get('english'),
item.get('python'),
item.get('java'),
int(item.get('english'))+int(item.get('python'))+int(item.get('java'))
))
(1)预期实现效果:统计学生信息文件中保存的学生信息条数。
(2)运行效果图

(3)业务流程图
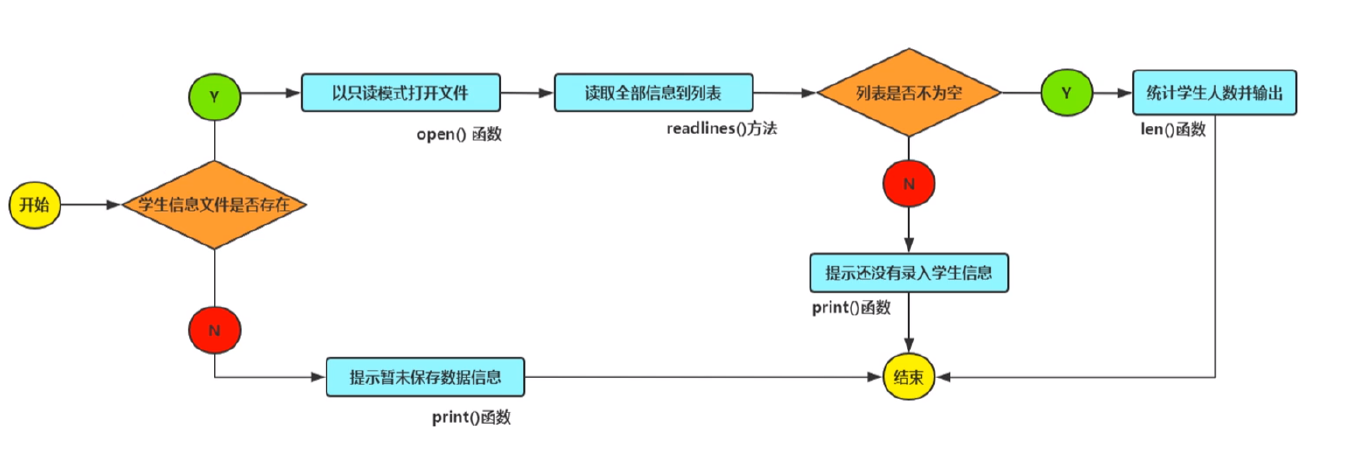
(4)total()函数源码
1
2
3
4
5
6
7
8
9
10
def total():
if os.path.exists(filename):
with open(filename,'r',encoding='utf-8') as rfile:
students = rfile.readlines()
if students:
print(f'一共有{len(students)}条信息')
else:
print('尚未录入学生信息')
else:
print('尚未保存学生信息')
(1)预期实现效果:将学生信息文件中保存的全部学生信息获取并显示。
(2)运行效果图
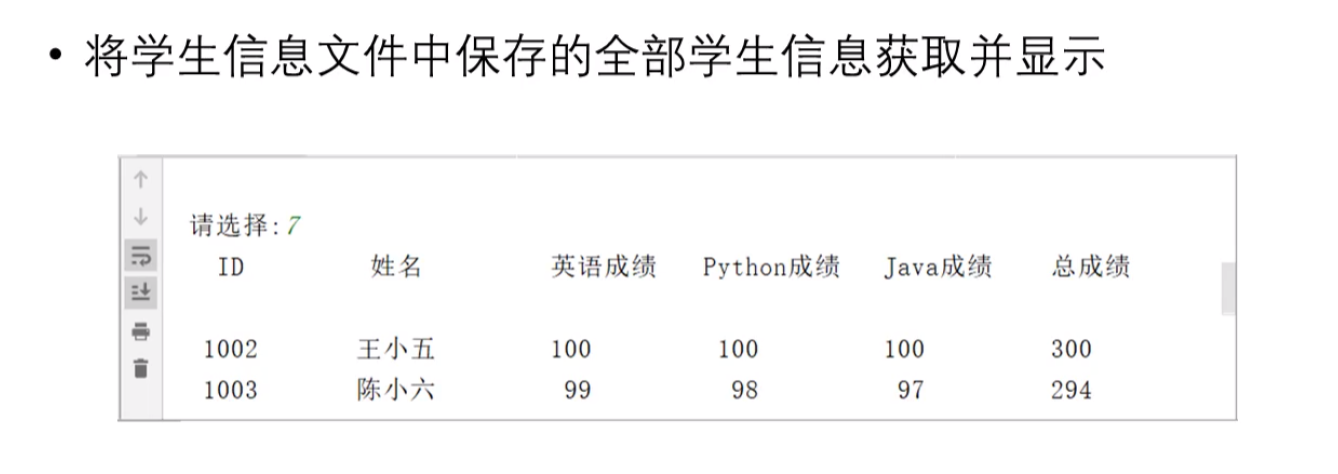
(3)业务流程图
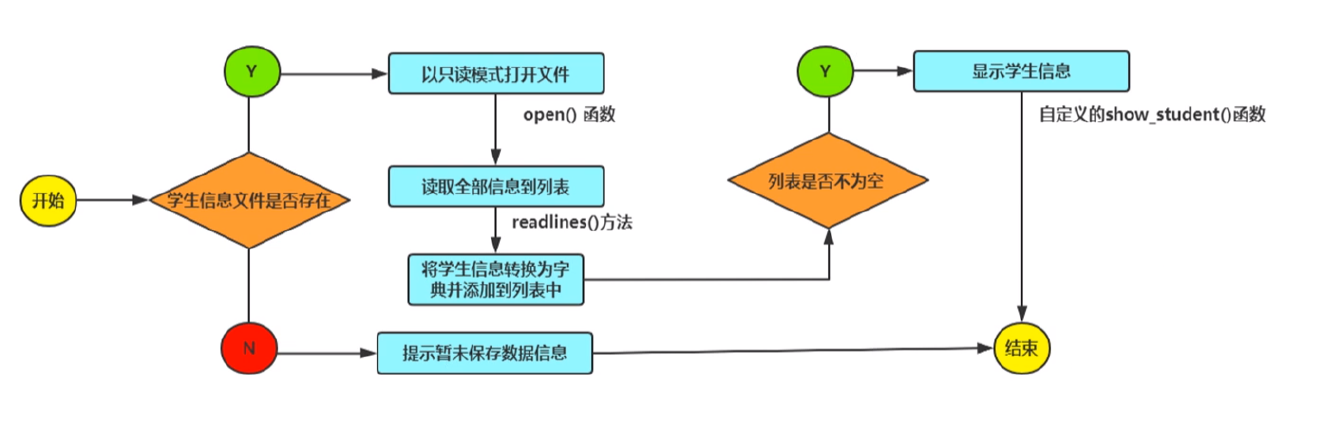
(4)show()函数源码
1
2
3
4
5
6
7
8
9
def show():
student_list = []
if os.path.exists(filename):
with open(filename,'r',encoding='utf-8') as rfile:
students = rfile.readlines()
for item in students:
student_list.append(eval(item))
if student_list:
show_student(student_list)
(1)预期实现效果:对学生信息按照各科成绩或总成绩进行升序或降序排序。
(2)运行效果图
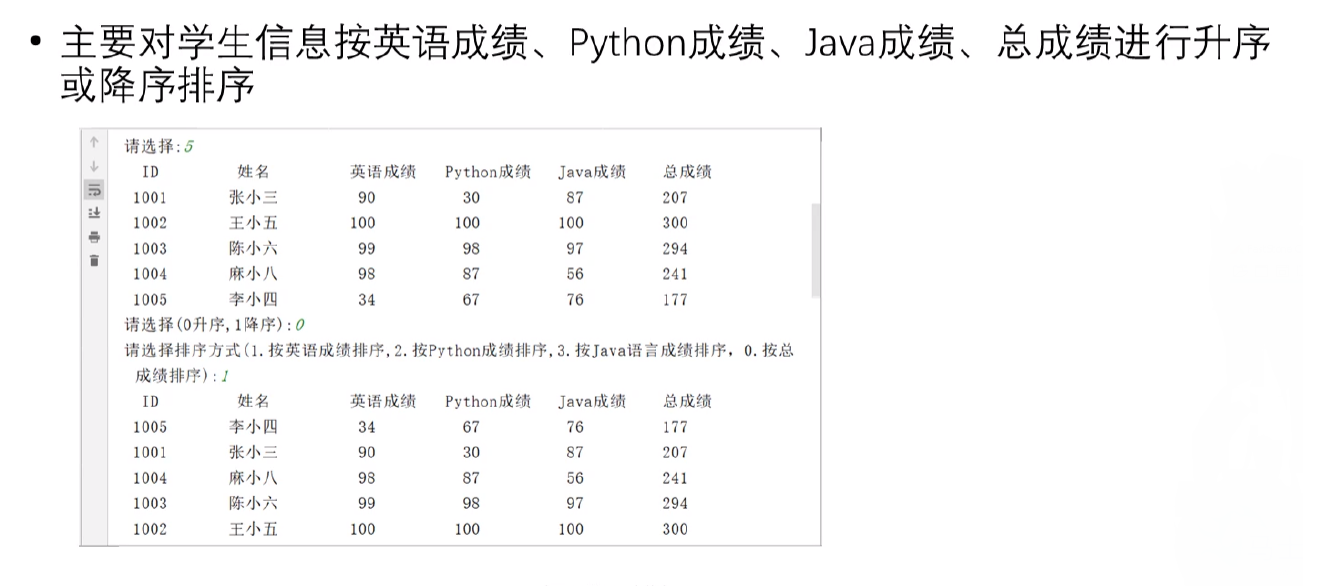
(3)业务流程图
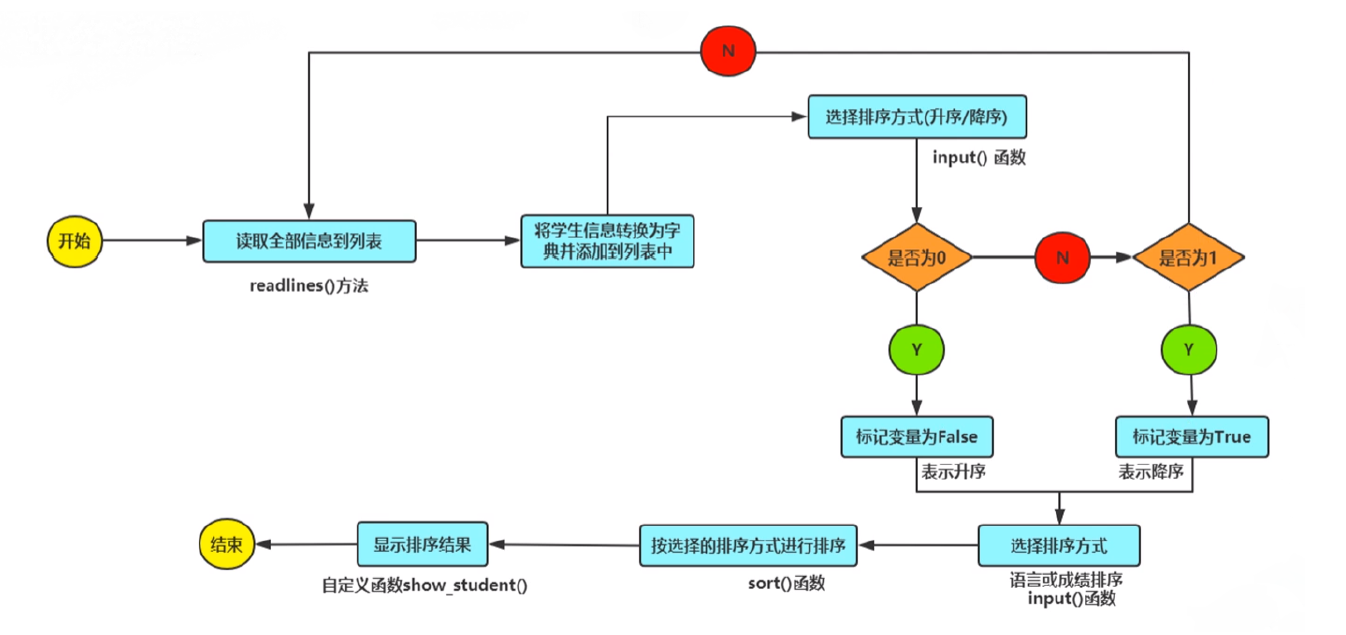
(4)sort()函数源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
def sort():
print('当前所有学生信息:\n')
show()
student_new = []
if os.path.exists(filename):
with open(filename,'r',encoding='utf-8') as rfile:
student_list = rfile.readlines()
for item in student_list:
d = dict(eval(item))
student_new.append(d)
else:
print('尚未录入学生信息')
return 0
asc_or_desc = input('请选择排序方式(0.升序 1.降序):')
if asc_or_desc == '0':
asc_or_desc_bool = False
elif asc_or_desc == '1':
asc_or_desc_bool = True
else:
print('输入有误,请重新输入!')
sort()
mode = input('请选择排序内容(1.按英语成绩排序 2.按Python成绩排序 3.按Java成绩排序 0.按总成绩排序):')
if mode == '1':
student_new.sort(key=lambda x:int(x['english']),reverse=asc_or_desc_bool) #使用匿名函数lambda
elif mode == '2':
student_new.sort(key=lambda x:int(x['python']),reverse=asc_or_desc)
elif mode == '3':
student_new.sort(key=lambda x:int(x['java']),reverse=asc_or_desc)
elif mode == '0':
student_new.sort(key=lambda x:int(x['english']+int(x['python']+int(x['java']))),reverse=asc_or_desc)
else:
print('输入有误,请重新输入!')
sort()
print('排序后的学生信息:')
show()
(1)工具:pyinstaller。
(2)安装(在线安装):在PyCharm的终端Terminal或者Python的交互式命令行下键入
1
pip install pyinstaller
然后回车等待即可。
(3)项目打包
语法格式:
1
pyinstaller [选项] Python 源文件路径
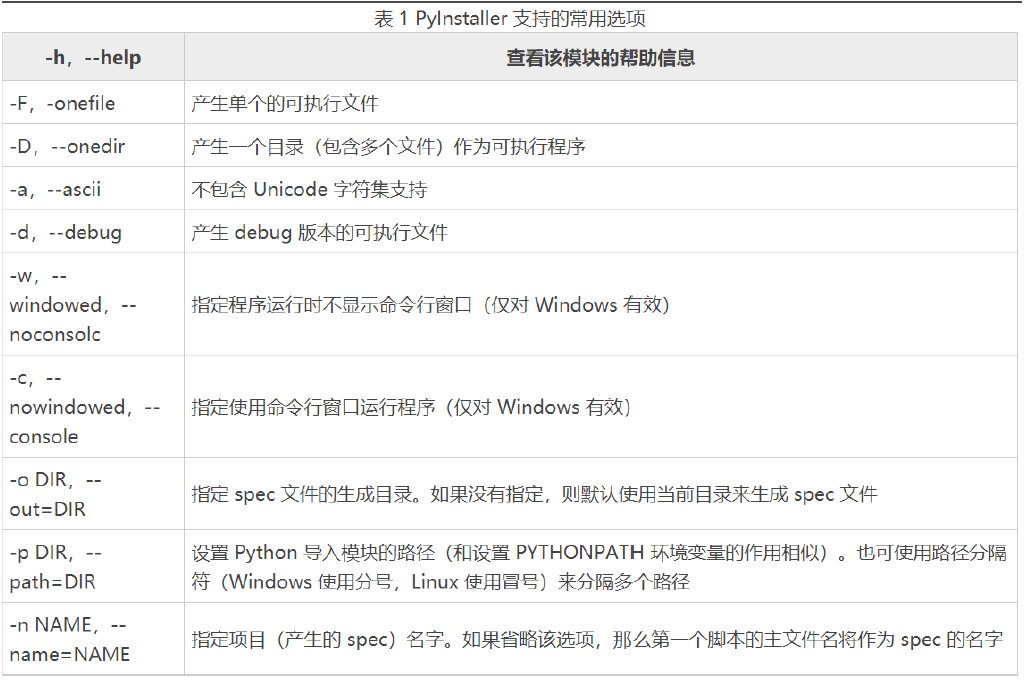
二、网络爬虫
TODO
三、数据分析
TODO