【论文阅读笔记】Hopper: Interpretative Fuzzing for Libraries
Hopper 论文阅读笔记存档

【论文阅读笔记】Hopper: Interpretative Fuzzing for Libraries
1. The Definition of Fuzzing
Fuzzing is one of the most popular techniques for finding software vulnerabilities.
Fuzzers give the software a large number of random inputs and observe whether unexpected behaviors happen.
2. What Problem HOPPER Mainly Solves
- Grey-box fuzzing in libraries is challenging:
- Users must manually craft a fuzz driver to consume type-agnostic inputs and transform byte streams into API arguments, which is time-consuming.
- Fuzzing a library built in a compile-based language requires recompilation every time arguments or call sequences change, which is also time-consuming.
- Hopper transforms the problem of library fuzzing into interpreter fuzzing to enhance efficiency.
- The coverage of APIs during library fuzzing tests through traditional methods (e.g., MCF, FuzzGen, GraphFuzz) is noticeably low.
- Putting all different API usages in sequence is inefficient since they have different search spaces for fuzzing.
- The blind byte stream generated by LibFuzzer makes it difficult to create structured inputs that satisfy intra-API constraints.
3. HOPPER’s Design
HOPPER is implemented mainly in Rust.
- Fuzzer: A grammar-aware fuzzer that generates inputs encoded in a DSL format.
- DSL:
load,call,update,assert,file - Grammar-aware Input Fuzzing:
- Pilot phase: Draw skeletons of the inputs and infer constraints via Algorithm 1.
- Evolution phase: Select and mutate the statements or calls of the program statements.
- Call statement mutation
- Type-aware value mutation
- Input minimization
- DSL:
- Interpreter: A lightweight interpreter that executes these inputs.
- Features: optional branch tracking, context-sensitive code coverage, overflow detection, use-after-free detection, comparison hooking
- Constraint Learning:
- Intra-API constraint: NON-NULL, FILE, EQUAL, RANGE, CAST (5 intra-API constraint inference rules)
- Inter-API constraint:
- Analyze function signatures initially to infer naive constraints between APIs.
- Track the coverage of APIs when a new API call is inserted before the target call, and find if any new call path is triggered, and which call leads to the new path.
- Cache effective arguments to ensure whether the new triggered call paths are introduced by the mutation of certain arguments.
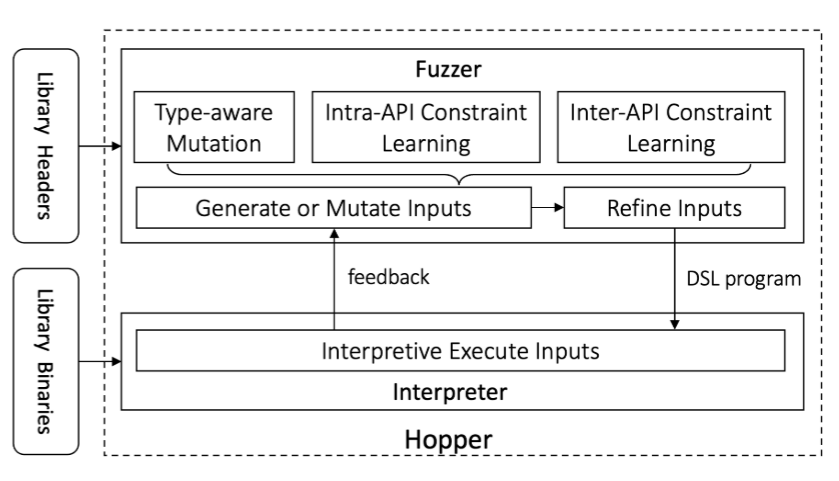 Figure 1: Overview of Hopper’s architecture.
Figure 1: Overview of Hopper’s architecture.
4. HOPPER’s Working Process
According to my understanding, HOPPER’s workflow can be described as below:
- Fuzzer analyzes the function signatures in the library’s C-like header files to get the initial intra-API and inter-API constraints.
- Fuzzer generates the initial DSL program, sending it to the interpreter.
- Interpreter executes the DSL program, gets the feedback, and sends it back to the fuzzer.
- Fuzzer analyzes the feedback and saves it to the seed pool, then mutates the program and minimizes input to construct a new DSL program.
- Repeat steps 3-4 until the fuzzing test completes.
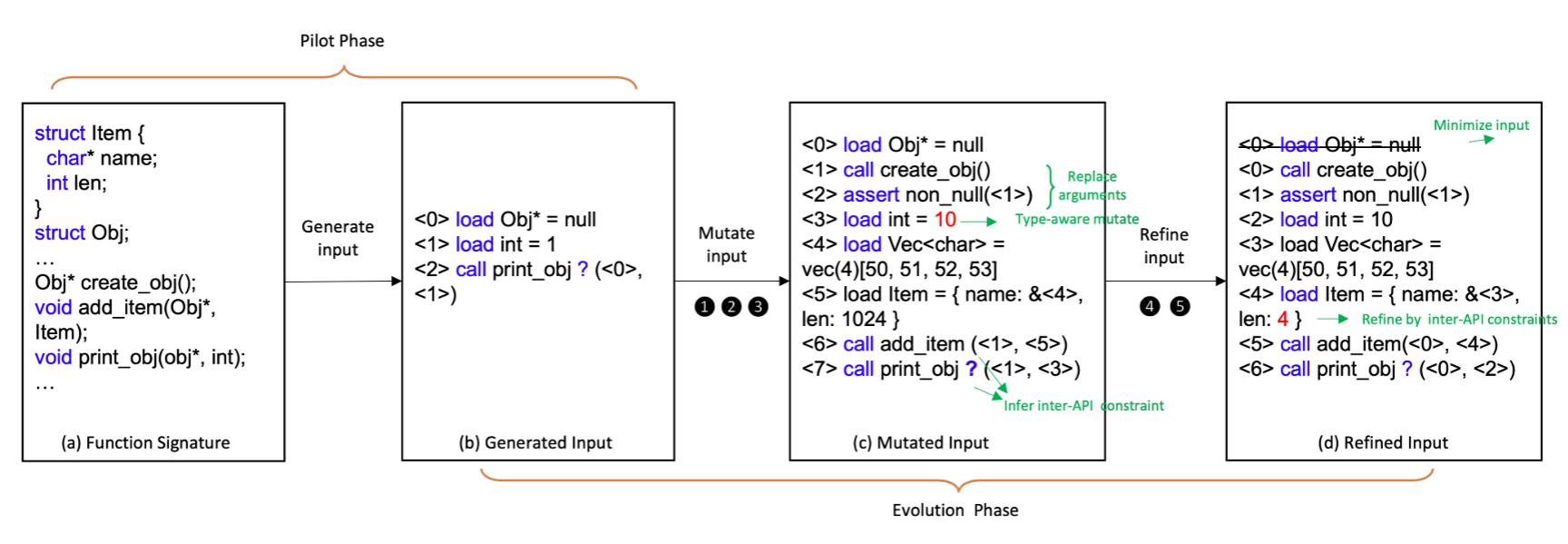 Figure 4: The workflow of input generation in Hopper.
Figure 4: The workflow of input generation in Hopper.
5. Experiments & Results
- Hopper outperformed MCFs and other library fuzzing approaches in terms of both code coverage and bug finding.
- Specifically, Hopper detects 25 new bugs and 17 of them have been confirmed.
- Hopper has the ability to learn intra-API constraints with high precision (96.51%) and recall (97.61%), while also being capable of speeding up the search process during fuzzing through the use of inter-API constraints.
- With grammar-aware input fuzzing, Hopper synthesizes programs that satisfy both intra- and inter-API constraints.
- Compared to MCFs, the programs generated by Hopper can explore a much broader range of API usages.
6. Discussion & Future Works
- Multiple-dimensional Search Space in Input Generation: The multi-dimensional nature of API input space requires the input generation method of fuzzer to be improved.
- Compatibility with C++ Libraries: It can’t support C++ library fuzzing now, to be addressed in future work.
- False Positive Crashes: Lack of methods for adding users’ custom constraints, leading to false positive crashes like false API usages.
7. Related Works & Reading Plan
- (Reading) (Literature Review) Zhu X, Wen S, Camtepe S, et al. Fuzzing: a survey for roadmap[J]. ACM Computing Surveys (CSUR), 2022, 54(11s): 1-36.
- (Reading) (Literature Review) Li J, Zhao B, Zhang C. Fuzzing: a survey[J]. Cybersecurity, 2018, 1: 1-13.
- (To be read) Ispoglou K, Austin D, Mohan V, et al. FuzzGen: Automatic fuzzer generation[C]//29th USENIX Security Symposium (USENIX Security 20). 2020: 2271-2287.
- (To be read) Green H, Avgerinos T. GraphFuzz: library API fuzzing with lifetime-aware dataflow graphs[C]//Proceedings of the 44th International Conference on Software Engineering. 2022: 1070-1081.
8. Source Code
Source code reading is challenging for me now since I’ve never learned Rust and the source code itself has a lot of files, which makes the project structure more ambiguous, but I’ll still try to read it slowly.
Maybe I should learn Rust first?
9. Questions after Reading
- Does HOPPER just circularly record the interpreter’s feedback and generate new DSL programs according to the feedback each epoch to implement its constraint learning mechanism?
Does HOPPER integrate more constraint learning methods? - Does HOPPER need to compile the original API source code called in the DSL program after it generates the DSL program?
Does HOPPER use compile-in instrumentation method or external instrumentation method? - Several literature have mentioned AFL as a classic benchmark for fuzz testing.
Should I read/learn AFL’s source code first?
This post is licensed under CC BY 4.0 by the author.